When you choose to publish with PLOS, your research makes an impact. Make your work accessible to all, without restrictions, and accelerate scientific discovery with options like preprints and published peer review that make your work more Open.
- PLOS Biology
- PLOS Climate
- PLOS Complex Systems
- PLOS Computational Biology
- PLOS Digital Health
- PLOS Genetics
- PLOS Global Public Health
- PLOS Medicine
- PLOS Mental Health
- PLOS Neglected Tropical Diseases
- PLOS Pathogens
- PLOS Sustainability and Transformation
- PLOS Collections
- How to Write Discussions and Conclusions

The discussion section contains the results and outcomes of a study. An effective discussion informs readers what can be learned from your experiment and provides context for the results.

What makes an effective discussion?
When you’re ready to write your discussion, you’ve already introduced the purpose of your study and provided an in-depth description of the methodology. The discussion informs readers about the larger implications of your study based on the results. Highlighting these implications while not overstating the findings can be challenging, especially when you’re submitting to a journal that selects articles based on novelty or potential impact. Regardless of what journal you are submitting to, the discussion section always serves the same purpose: concluding what your study results actually mean.
A successful discussion section puts your findings in context. It should include:
- the results of your research,
- a discussion of related research, and
- a comparison between your results and initial hypothesis.
Tip: Not all journals share the same naming conventions.
You can apply the advice in this article to the conclusion, results or discussion sections of your manuscript.
Our Early Career Researcher community tells us that the conclusion is often considered the most difficult aspect of a manuscript to write. To help, this guide provides questions to ask yourself, a basic structure to model your discussion off of and examples from published manuscripts.
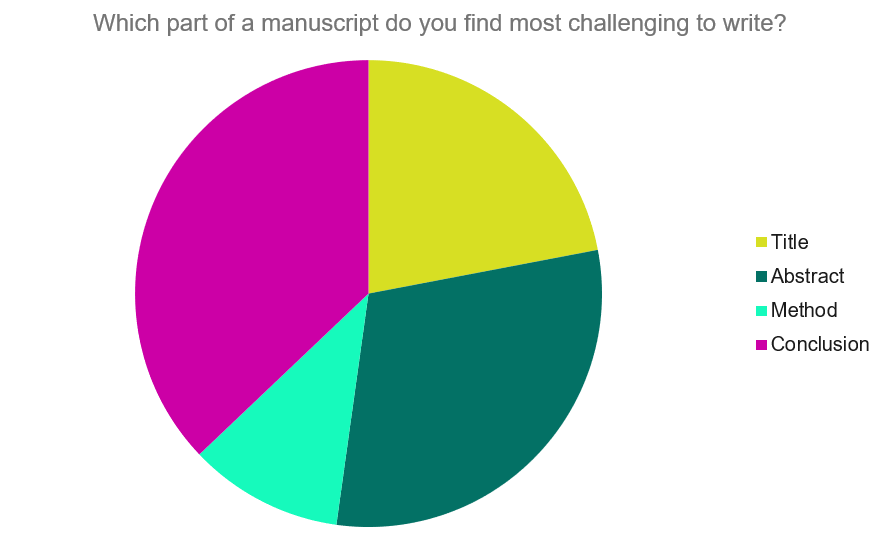
Questions to ask yourself:
- Was my hypothesis correct?
- If my hypothesis is partially correct or entirely different, what can be learned from the results?
- How do the conclusions reshape or add onto the existing knowledge in the field? What does previous research say about the topic?
- Why are the results important or relevant to your audience? Do they add further evidence to a scientific consensus or disprove prior studies?
- How can future research build on these observations? What are the key experiments that must be done?
- What is the “take-home” message you want your reader to leave with?
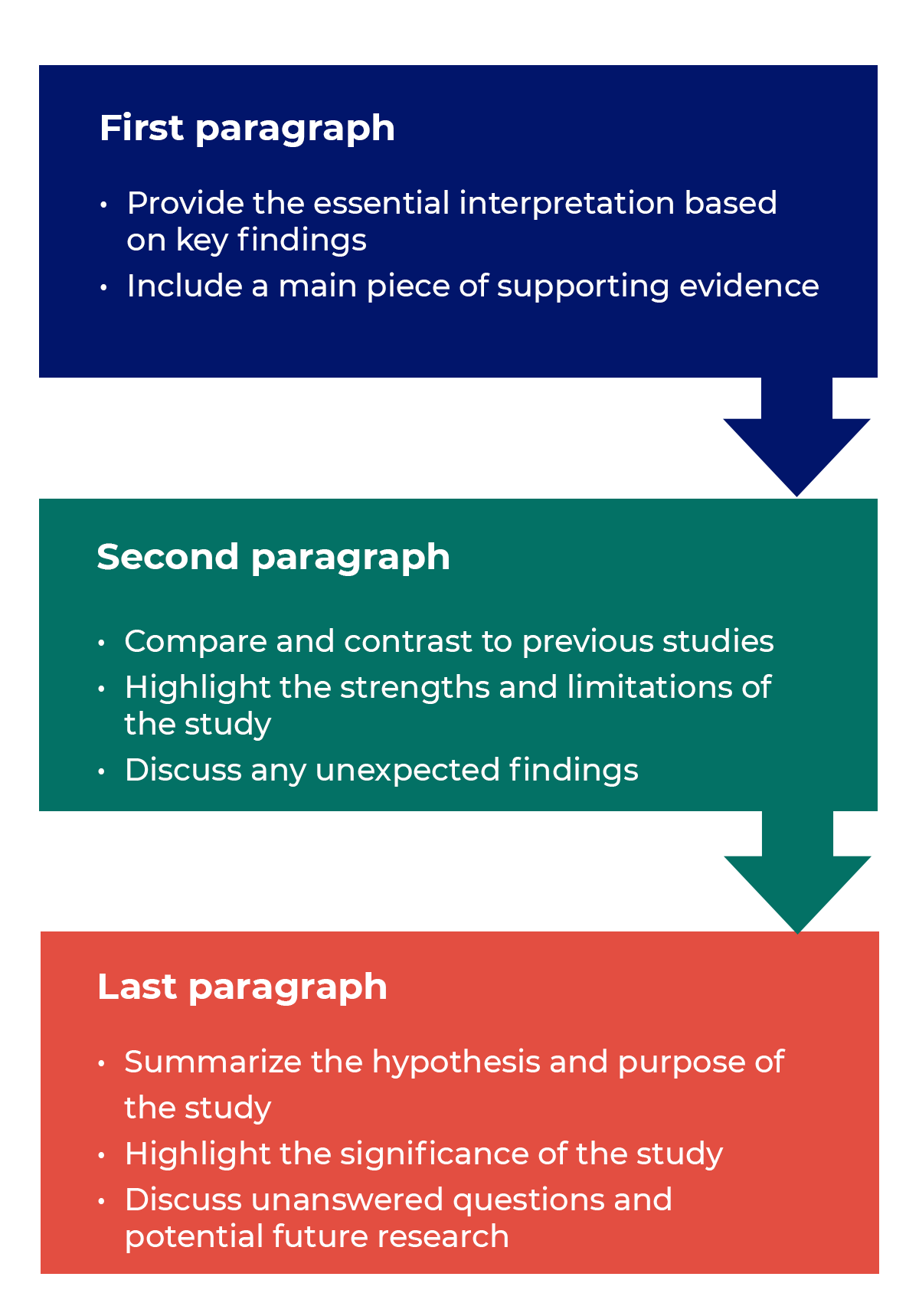
How to structure a discussion
Trying to fit a complete discussion into a single paragraph can add unnecessary stress to the writing process. If possible, you’ll want to give yourself two or three paragraphs to give the reader a comprehensive understanding of your study as a whole. Here’s one way to structure an effective discussion:
Writing Tips
While the above sections can help you brainstorm and structure your discussion, there are many common mistakes that writers revert to when having difficulties with their paper. Writing a discussion can be a delicate balance between summarizing your results, providing proper context for your research and avoiding introducing new information. Remember that your paper should be both confident and honest about the results!

- Read the journal’s guidelines on the discussion and conclusion sections. If possible, learn about the guidelines before writing the discussion to ensure you’re writing to meet their expectations.
- Begin with a clear statement of the principal findings. This will reinforce the main take-away for the reader and set up the rest of the discussion.
- Explain why the outcomes of your study are important to the reader. Discuss the implications of your findings realistically based on previous literature, highlighting both the strengths and limitations of the research.
- State whether the results prove or disprove your hypothesis. If your hypothesis was disproved, what might be the reasons?
- Introduce new or expanded ways to think about the research question. Indicate what next steps can be taken to further pursue any unresolved questions.
- If dealing with a contemporary or ongoing problem, such as climate change, discuss possible consequences if the problem is avoided.
- Be concise. Adding unnecessary detail can distract from the main findings.

Don’t
- Rewrite your abstract. Statements with “we investigated” or “we studied” generally do not belong in the discussion.
- Include new arguments or evidence not previously discussed. Necessary information and evidence should be introduced in the main body of the paper.
- Apologize. Even if your research contains significant limitations, don’t undermine your authority by including statements that doubt your methodology or execution.
- Shy away from speaking on limitations or negative results. Including limitations and negative results will give readers a complete understanding of the presented research. Potential limitations include sources of potential bias, threats to internal or external validity, barriers to implementing an intervention and other issues inherent to the study design.
- Overstate the importance of your findings. Making grand statements about how a study will fully resolve large questions can lead readers to doubt the success of the research.
Snippets of Effective Discussions:
Consumer-based actions to reduce plastic pollution in rivers: A multi-criteria decision analysis approach
Identifying reliable indicators of fitness in polar bears
- How to Write a Great Title
- How to Write an Abstract
- How to Write Your Methods
- How to Report Statistics
- How to Edit Your Work
The contents of the Peer Review Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
The contents of the Writing Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
There’s a lot to consider when deciding where to submit your work. Learn how to choose a journal that will help your study reach its audience, while reflecting your values as a researcher…
How to Write the Discussion Section of a Research Paper
The discussion section of a research paper analyzes and interprets the findings, provides context, compares them with previous studies, identifies limitations, and suggests future research directions.
Updated on September 15, 2023

Structure your discussion section right, and you’ll be cited more often while doing a greater service to the scientific community. So, what actually goes into the discussion section? And how do you write it?
The discussion section of your research paper is where you let the reader know how your study is positioned in the literature, what to take away from your paper, and how your work helps them. It can also include your conclusions and suggestions for future studies.
First, we’ll define all the parts of your discussion paper, and then look into how to write a strong, effective discussion section for your paper or manuscript.
Discussion section: what is it, what it does
The discussion section comes later in your paper, following the introduction, methods, and results. The discussion sets up your study’s conclusions. Its main goals are to present, interpret, and provide a context for your results.
What is it?
The discussion section provides an analysis and interpretation of the findings, compares them with previous studies, identifies limitations, and suggests future directions for research.
This section combines information from the preceding parts of your paper into a coherent story. By this point, the reader already knows why you did your study (introduction), how you did it (methods), and what happened (results). In the discussion, you’ll help the reader connect the ideas from these sections.
Why is it necessary?
The discussion provides context and interpretations for the results. It also answers the questions posed in the introduction. While the results section describes your findings, the discussion explains what they say. This is also where you can describe the impact or implications of your research.
Adds context for your results
Most research studies aim to answer a question, replicate a finding, or address limitations in the literature. These goals are first described in the introduction. However, in the discussion section, the author can refer back to them to explain how the study's objective was achieved.
Shows what your results actually mean and real-world implications
The discussion can also describe the effect of your findings on research or practice. How are your results significant for readers, other researchers, or policymakers?
What to include in your discussion (in the correct order)
A complete and effective discussion section should at least touch on the points described below.
Summary of key findings
The discussion should begin with a brief factual summary of the results. Concisely overview the main results you obtained.
Begin with key findings with supporting evidence
Your results section described a list of findings, but what message do they send when you look at them all together?
Your findings were detailed in the results section, so there’s no need to repeat them here, but do provide at least a few highlights. This will help refresh the reader’s memory and help them focus on the big picture.
Read the first paragraph of the discussion section in this article (PDF) for an example of how to start this part of your paper. Notice how the authors break down their results and follow each description sentence with an explanation of why each finding is relevant.
State clearly and concisely
Following a clear and direct writing style is especially important in the discussion section. After all, this is where you will make some of the most impactful points in your paper. While the results section often contains technical vocabulary, such as statistical terms, the discussion section lets you describe your findings more clearly.
Interpretation of results
Once you’ve given your reader an overview of your results, you need to interpret those results. In other words, what do your results mean? Discuss the findings’ implications and significance in relation to your research question or hypothesis.
Analyze and interpret your findings
Look into your findings and explore what’s behind them or what may have caused them. If your introduction cited theories or studies that could explain your findings, use these sources as a basis to discuss your results.
For example, look at the second paragraph in the discussion section of this article on waggling honey bees. Here, the authors explore their results based on information from the literature.
Unexpected or contradictory results
Sometimes, your findings are not what you expect. Here’s where you describe this and try to find a reason for it. Could it be because of the method you used? Does it have something to do with the variables analyzed? Comparing your methods with those of other similar studies can help with this task.
Context and comparison with previous work
Refer to related studies to place your research in a larger context and the literature. Compare and contrast your findings with existing literature, highlighting similarities, differences, and/or contradictions.
How your work compares or contrasts with previous work
Studies with similar findings to yours can be cited to show the strength of your findings. Information from these studies can also be used to help explain your results. Differences between your findings and others in the literature can also be discussed here.
How to divide this section into subsections
If you have more than one objective in your study or many key findings, you can dedicate a separate section to each of these. Here’s an example of this approach. You can see that the discussion section is divided into topics and even has a separate heading for each of them.
Limitations
Many journals require you to include the limitations of your study in the discussion. Even if they don’t, there are good reasons to mention these in your paper.
Why limitations don’t have a negative connotation
A study’s limitations are points to be improved upon in future research. While some of these may be flaws in your method, many may be due to factors you couldn’t predict.
Examples include time constraints or small sample sizes. Pointing this out will help future researchers avoid or address these issues. This part of the discussion can also include any attempts you have made to reduce the impact of these limitations, as in this study .
How limitations add to a researcher's credibility
Pointing out the limitations of your study demonstrates transparency. It also shows that you know your methods well and can conduct a critical assessment of them.
Implications and significance
The final paragraph of the discussion section should contain the take-home messages for your study. It can also cite the “strong points” of your study, to contrast with the limitations section.
Restate your hypothesis
Remind the reader what your hypothesis was before you conducted the study.
How was it proven or disproven?
Identify your main findings and describe how they relate to your hypothesis.
How your results contribute to the literature
Were you able to answer your research question? Or address a gap in the literature?
Future implications of your research
Describe the impact that your results may have on the topic of study. Your results may show, for instance, that there are still limitations in the literature for future studies to address. There may be a need for studies that extend your findings in a specific way. You also may need additional research to corroborate your findings.
Sample discussion section
This fictitious example covers all the aspects discussed above. Your actual discussion section will probably be much longer, but you can read this to get an idea of everything your discussion should cover.
Our results showed that the presence of cats in a household is associated with higher levels of perceived happiness by its human occupants. These findings support our hypothesis and demonstrate the association between pet ownership and well-being.
The present findings align with those of Bao and Schreer (2016) and Hardie et al. (2023), who observed greater life satisfaction in pet owners relative to non-owners. Although the present study did not directly evaluate life satisfaction, this factor may explain the association between happiness and cat ownership observed in our sample.
Our findings must be interpreted in light of some limitations, such as the focus on cat ownership only rather than pets as a whole. This may limit the generalizability of our results.
Nevertheless, this study had several strengths. These include its strict exclusion criteria and use of a standardized assessment instrument to investigate the relationships between pets and owners. These attributes bolster the accuracy of our results and reduce the influence of confounding factors, increasing the strength of our conclusions. Future studies may examine the factors that mediate the association between pet ownership and happiness to better comprehend this phenomenon.
This brief discussion begins with a quick summary of the results and hypothesis. The next paragraph cites previous research and compares its findings to those of this study. Information from previous studies is also used to help interpret the findings. After discussing the results of the study, some limitations are pointed out. The paper also explains why these limitations may influence the interpretation of results. Then, final conclusions are drawn based on the study, and directions for future research are suggested.
How to make your discussion flow naturally
If you find writing in scientific English challenging, the discussion and conclusions are often the hardest parts of the paper to write. That’s because you’re not just listing up studies, methods, and outcomes. You’re actually expressing your thoughts and interpretations in words.
- How formal should it be?
- What words should you use, or not use?
- How do you meet strict word limits, or make it longer and more informative?
Always give it your best, but sometimes a helping hand can, well, help. Getting a professional edit can help clarify your work’s importance while improving the English used to explain it. When readers know the value of your work, they’ll cite it. We’ll assign your study to an expert editor knowledgeable in your area of research. Their work will clarify your discussion, helping it to tell your story. Find out more about AJE Editing.

Adam Goulston, PsyD, MS, MBA, MISD, ELS
Science Marketing Consultant
See our "Privacy Policy"
Ensure your structure and ideas are consistent and clearly communicated
Pair your Premium Editing with our add-on service Presubmission Review for an overall assessment of your manuscript.
Generate accurate APA citations for free
- Knowledge Base
- APA Style 7th edition
- How to write an APA results section
Reporting Research Results in APA Style | Tips & Examples
Published on December 21, 2020 by Pritha Bhandari . Revised on January 17, 2024.
The results section of a quantitative research paper is where you summarize your data and report the findings of any relevant statistical analyses.
The APA manual provides rigorous guidelines for what to report in quantitative research papers in the fields of psychology, education, and other social sciences.
Use these standards to answer your research questions and report your data analyses in a complete and transparent way.
Instantly correct all language mistakes in your text
Upload your document to correct all your mistakes in minutes

Table of contents
What goes in your results section, introduce your data, summarize your data, report statistical results, presenting numbers effectively, what doesn’t belong in your results section, frequently asked questions about results in apa.
In APA style, the results section includes preliminary information about the participants and data, descriptive and inferential statistics, and the results of any exploratory analyses.
Include these in your results section:
- Participant flow and recruitment period. Report the number of participants at every stage of the study, as well as the dates when recruitment took place.
- Missing data . Identify the proportion of data that wasn’t included in your final analysis and state the reasons.
- Any adverse events. Make sure to report any unexpected events or side effects (for clinical studies).
- Descriptive statistics . Summarize the primary and secondary outcomes of the study.
- Inferential statistics , including confidence intervals and effect sizes. Address the primary and secondary research questions by reporting the detailed results of your main analyses.
- Results of subgroup or exploratory analyses, if applicable. Place detailed results in supplementary materials.
Write up the results in the past tense because you’re describing the outcomes of a completed research study.
Prevent plagiarism. Run a free check.
Before diving into your research findings, first describe the flow of participants at every stage of your study and whether any data were excluded from the final analysis.
Participant flow and recruitment period
It’s necessary to report any attrition, which is the decline in participants at every sequential stage of a study. That’s because an uneven number of participants across groups sometimes threatens internal validity and makes it difficult to compare groups. Be sure to also state all reasons for attrition.
If your study has multiple stages (e.g., pre-test, intervention, and post-test) and groups (e.g., experimental and control groups), a flow chart is the best way to report the number of participants in each group per stage and reasons for attrition.
Also report the dates for when you recruited participants or performed follow-up sessions.
Missing data
Another key issue is the completeness of your dataset. It’s necessary to report both the amount and reasons for data that was missing or excluded.
Data can become unusable due to equipment malfunctions, improper storage, unexpected events, participant ineligibility, and so on. For each case, state the reason why the data were unusable.
Some data points may be removed from the final analysis because they are outliers—but you must be able to justify how you decided what to exclude.
If you applied any techniques for overcoming or compensating for lost data, report those as well.
Adverse events
For clinical studies, report all events with serious consequences or any side effects that occured.
Descriptive statistics summarize your data for the reader. Present descriptive statistics for each primary, secondary, and subgroup analysis.
Don’t provide formulas or citations for commonly used statistics (e.g., standard deviation) – but do provide them for new or rare equations.
Descriptive statistics
The exact descriptive statistics that you report depends on the types of data in your study. Categorical variables can be reported using proportions, while quantitative data can be reported using means and standard deviations . For a large set of numbers, a table is the most effective presentation format.
Include sample sizes (overall and for each group) as well as appropriate measures of central tendency and variability for the outcomes in your results section. For every point estimate , add a clearly labelled measure of variability as well.
Be sure to note how you combined data to come up with variables of interest. For every variable of interest, explain how you operationalized it.
According to APA journal standards, it’s necessary to report all relevant hypothesis tests performed, estimates of effect sizes, and confidence intervals.
When reporting statistical results, you should first address primary research questions before moving onto secondary research questions and any exploratory or subgroup analyses.
Present the results of tests in the order that you performed them—report the outcomes of main tests before post-hoc tests, for example. Don’t leave out any relevant results, even if they don’t support your hypothesis.
Inferential statistics
For each statistical test performed, first restate the hypothesis , then state whether your hypothesis was supported and provide the outcomes that led you to that conclusion.
Report the following for each hypothesis test:
- the test statistic value,
- the degrees of freedom ,
- the exact p- value (unless it is less than 0.001),
- the magnitude and direction of the effect.
When reporting complex data analyses, such as factor analysis or multivariate analysis, present the models estimated in detail, and state the statistical software used. Make sure to report any violations of statistical assumptions or problems with estimation.
Effect sizes and confidence intervals
For each hypothesis test performed, you should present confidence intervals and estimates of effect sizes .
Confidence intervals are useful for showing the variability around point estimates. They should be included whenever you report population parameter estimates.
Effect sizes indicate how impactful the outcomes of a study are. But since they are estimates, it’s recommended that you also provide confidence intervals of effect sizes.
Subgroup or exploratory analyses
Briefly report the results of any other planned or exploratory analyses you performed. These may include subgroup analyses as well.
Subgroup analyses come with a high chance of false positive results, because performing a large number of comparison or correlation tests increases the chances of finding significant results.
If you find significant results in these analyses, make sure to appropriately report them as exploratory (rather than confirmatory) results to avoid overstating their importance.
While these analyses can be reported in less detail in the main text, you can provide the full analyses in supplementary materials.
Scribbr Citation Checker New
The AI-powered Citation Checker helps you avoid common mistakes such as:
- Missing commas and periods
- Incorrect usage of “et al.”
- Ampersands (&) in narrative citations
- Missing reference entries

To effectively present numbers, use a mix of text, tables , and figures where appropriate:
- To present three or fewer numbers, try a sentence ,
- To present between 4 and 20 numbers, try a table ,
- To present more than 20 numbers, try a figure .
Since these are general guidelines, use your own judgment and feedback from others for effective presentation of numbers.
Tables and figures should be numbered and have titles, along with relevant notes. Make sure to present data only once throughout the paper and refer to any tables and figures in the text.
Formatting statistics and numbers
It’s important to follow capitalization , italicization, and abbreviation rules when referring to statistics in your paper. There are specific format guidelines for reporting statistics in APA , as well as general rules about writing numbers .
If you are unsure of how to present specific symbols, look up the detailed APA guidelines or other papers in your field.
It’s important to provide a complete picture of your data analyses and outcomes in a concise way. For that reason, raw data and any interpretations of your results are not included in the results section.
It’s rarely appropriate to include raw data in your results section. Instead, you should always save the raw data securely and make them available and accessible to any other researchers who request them.
Making scientific research available to others is a key part of academic integrity and open science.
Interpretation or discussion of results
This belongs in your discussion section. Your results section is where you objectively report all relevant findings and leave them open for interpretation by readers.
While you should state whether the findings of statistical tests lend support to your hypotheses, refrain from forming conclusions to your research questions in the results section.
Explanation of how statistics tests work
For the sake of concise writing, you can safely assume that readers of your paper have professional knowledge of how statistical inferences work.
In an APA results section , you should generally report the following:
- Participant flow and recruitment period.
- Missing data and any adverse events.
- Descriptive statistics about your samples.
- Inferential statistics , including confidence intervals and effect sizes.
- Results of any subgroup or exploratory analyses, if applicable.
According to the APA guidelines, you should report enough detail on inferential statistics so that your readers understand your analyses.
- the test statistic value
- the degrees of freedom
- the exact p value (unless it is less than 0.001)
- the magnitude and direction of the effect
You should also present confidence intervals and estimates of effect sizes where relevant.
In APA style, statistics can be presented in the main text or as tables or figures . To decide how to present numbers, you can follow APA guidelines:
- To present three or fewer numbers, try a sentence,
- To present between 4 and 20 numbers, try a table,
- To present more than 20 numbers, try a figure.
Results are usually written in the past tense , because they are describing the outcome of completed actions.
The results chapter or section simply and objectively reports what you found, without speculating on why you found these results. The discussion interprets the meaning of the results, puts them in context, and explains why they matter.
In qualitative research , results and discussion are sometimes combined. But in quantitative research , it’s considered important to separate the objective results from your interpretation of them.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bhandari, P. (2024, January 17). Reporting Research Results in APA Style | Tips & Examples. Scribbr. Retrieved March 15, 2024, from https://www.scribbr.com/apa-style/results-section/
Is this article helpful?

Pritha Bhandari
Other students also liked, how to write an apa methods section, how to format tables and figures in apa style, reporting statistics in apa style | guidelines & examples, scribbr apa citation checker.
An innovative new tool that checks your APA citations with AI software. Say goodbye to inaccurate citations!
- Privacy Policy
Buy Me a Coffee
Home » Research Results Section – Writing Guide and Examples
Research Results Section – Writing Guide and Examples
Table of Contents

Research Results
Research results refer to the findings and conclusions derived from a systematic investigation or study conducted to answer a specific question or hypothesis. These results are typically presented in a written report or paper and can include various forms of data such as numerical data, qualitative data, statistics, charts, graphs, and visual aids.
Results Section in Research
The results section of the research paper presents the findings of the study. It is the part of the paper where the researcher reports the data collected during the study and analyzes it to draw conclusions.
In the results section, the researcher should describe the data that was collected, the statistical analysis performed, and the findings of the study. It is important to be objective and not interpret the data in this section. Instead, the researcher should report the data as accurately and objectively as possible.
Structure of Research Results Section
The structure of the research results section can vary depending on the type of research conducted, but in general, it should contain the following components:
- Introduction: The introduction should provide an overview of the study, its aims, and its research questions. It should also briefly explain the methodology used to conduct the study.
- Data presentation : This section presents the data collected during the study. It may include tables, graphs, or other visual aids to help readers better understand the data. The data presented should be organized in a logical and coherent way, with headings and subheadings used to help guide the reader.
- Data analysis: In this section, the data presented in the previous section are analyzed and interpreted. The statistical tests used to analyze the data should be clearly explained, and the results of the tests should be presented in a way that is easy to understand.
- Discussion of results : This section should provide an interpretation of the results of the study, including a discussion of any unexpected findings. The discussion should also address the study’s research questions and explain how the results contribute to the field of study.
- Limitations: This section should acknowledge any limitations of the study, such as sample size, data collection methods, or other factors that may have influenced the results.
- Conclusions: The conclusions should summarize the main findings of the study and provide a final interpretation of the results. The conclusions should also address the study’s research questions and explain how the results contribute to the field of study.
- Recommendations : This section may provide recommendations for future research based on the study’s findings. It may also suggest practical applications for the study’s results in real-world settings.
Outline of Research Results Section
The following is an outline of the key components typically included in the Results section:
I. Introduction
- A brief overview of the research objectives and hypotheses
- A statement of the research question
II. Descriptive statistics
- Summary statistics (e.g., mean, standard deviation) for each variable analyzed
- Frequencies and percentages for categorical variables
III. Inferential statistics
- Results of statistical analyses, including tests of hypotheses
- Tables or figures to display statistical results
IV. Effect sizes and confidence intervals
- Effect sizes (e.g., Cohen’s d, odds ratio) to quantify the strength of the relationship between variables
- Confidence intervals to estimate the range of plausible values for the effect size
V. Subgroup analyses
- Results of analyses that examined differences between subgroups (e.g., by gender, age, treatment group)
VI. Limitations and assumptions
- Discussion of any limitations of the study and potential sources of bias
- Assumptions made in the statistical analyses
VII. Conclusions
- A summary of the key findings and their implications
- A statement of whether the hypotheses were supported or not
- Suggestions for future research
Example of Research Results Section
An Example of a Research Results Section could be:
- This study sought to examine the relationship between sleep quality and academic performance in college students.
- Hypothesis : College students who report better sleep quality will have higher GPAs than those who report poor sleep quality.
- Methodology : Participants completed a survey about their sleep habits and academic performance.
II. Participants
- Participants were college students (N=200) from a mid-sized public university in the United States.
- The sample was evenly split by gender (50% female, 50% male) and predominantly white (85%).
- Participants were recruited through flyers and online advertisements.
III. Results
- Participants who reported better sleep quality had significantly higher GPAs (M=3.5, SD=0.5) than those who reported poor sleep quality (M=2.9, SD=0.6).
- See Table 1 for a summary of the results.
- Participants who reported consistent sleep schedules had higher GPAs than those with irregular sleep schedules.
IV. Discussion
- The results support the hypothesis that better sleep quality is associated with higher academic performance in college students.
- These findings have implications for college students, as prioritizing sleep could lead to better academic outcomes.
- Limitations of the study include self-reported data and the lack of control for other variables that could impact academic performance.
V. Conclusion
- College students who prioritize sleep may see a positive impact on their academic performance.
- These findings highlight the importance of sleep in academic success.
- Future research could explore interventions to improve sleep quality in college students.
Example of Research Results in Research Paper :
Our study aimed to compare the performance of three different machine learning algorithms (Random Forest, Support Vector Machine, and Neural Network) in predicting customer churn in a telecommunications company. We collected a dataset of 10,000 customer records, with 20 predictor variables and a binary churn outcome variable.
Our analysis revealed that all three algorithms performed well in predicting customer churn, with an overall accuracy of 85%. However, the Random Forest algorithm showed the highest accuracy (88%), followed by the Support Vector Machine (86%) and the Neural Network (84%).
Furthermore, we found that the most important predictor variables for customer churn were monthly charges, contract type, and tenure. Random Forest identified monthly charges as the most important variable, while Support Vector Machine and Neural Network identified contract type as the most important.
Overall, our results suggest that machine learning algorithms can be effective in predicting customer churn in a telecommunications company, and that Random Forest is the most accurate algorithm for this task.
Example 3 :
Title : The Impact of Social Media on Body Image and Self-Esteem
Abstract : This study aimed to investigate the relationship between social media use, body image, and self-esteem among young adults. A total of 200 participants were recruited from a university and completed self-report measures of social media use, body image satisfaction, and self-esteem.
Results: The results showed that social media use was significantly associated with body image dissatisfaction and lower self-esteem. Specifically, participants who reported spending more time on social media platforms had lower levels of body image satisfaction and self-esteem compared to those who reported less social media use. Moreover, the study found that comparing oneself to others on social media was a significant predictor of body image dissatisfaction and lower self-esteem.
Conclusion : These results suggest that social media use can have negative effects on body image satisfaction and self-esteem among young adults. It is important for individuals to be mindful of their social media use and to recognize the potential negative impact it can have on their mental health. Furthermore, interventions aimed at promoting positive body image and self-esteem should take into account the role of social media in shaping these attitudes and behaviors.
Importance of Research Results
Research results are important for several reasons, including:
- Advancing knowledge: Research results can contribute to the advancement of knowledge in a particular field, whether it be in science, technology, medicine, social sciences, or humanities.
- Developing theories: Research results can help to develop or modify existing theories and create new ones.
- Improving practices: Research results can inform and improve practices in various fields, such as education, healthcare, business, and public policy.
- Identifying problems and solutions: Research results can identify problems and provide solutions to complex issues in society, including issues related to health, environment, social justice, and economics.
- Validating claims : Research results can validate or refute claims made by individuals or groups in society, such as politicians, corporations, or activists.
- Providing evidence: Research results can provide evidence to support decision-making, policy-making, and resource allocation in various fields.
How to Write Results in A Research Paper
Here are some general guidelines on how to write results in a research paper:
- Organize the results section: Start by organizing the results section in a logical and coherent manner. Divide the section into subsections if necessary, based on the research questions or hypotheses.
- Present the findings: Present the findings in a clear and concise manner. Use tables, graphs, and figures to illustrate the data and make the presentation more engaging.
- Describe the data: Describe the data in detail, including the sample size, response rate, and any missing data. Provide relevant descriptive statistics such as means, standard deviations, and ranges.
- Interpret the findings: Interpret the findings in light of the research questions or hypotheses. Discuss the implications of the findings and the extent to which they support or contradict existing theories or previous research.
- Discuss the limitations : Discuss the limitations of the study, including any potential sources of bias or confounding factors that may have affected the results.
- Compare the results : Compare the results with those of previous studies or theoretical predictions. Discuss any similarities, differences, or inconsistencies.
- Avoid redundancy: Avoid repeating information that has already been presented in the introduction or methods sections. Instead, focus on presenting new and relevant information.
- Be objective: Be objective in presenting the results, avoiding any personal biases or interpretations.
When to Write Research Results
Here are situations When to Write Research Results”
- After conducting research on the chosen topic and obtaining relevant data, organize the findings in a structured format that accurately represents the information gathered.
- Once the data has been analyzed and interpreted, and conclusions have been drawn, begin the writing process.
- Before starting to write, ensure that the research results adhere to the guidelines and requirements of the intended audience, such as a scientific journal or academic conference.
- Begin by writing an abstract that briefly summarizes the research question, methodology, findings, and conclusions.
- Follow the abstract with an introduction that provides context for the research, explains its significance, and outlines the research question and objectives.
- The next section should be a literature review that provides an overview of existing research on the topic and highlights the gaps in knowledge that the current research seeks to address.
- The methodology section should provide a detailed explanation of the research design, including the sample size, data collection methods, and analytical techniques used.
- Present the research results in a clear and concise manner, using graphs, tables, and figures to illustrate the findings.
- Discuss the implications of the research results, including how they contribute to the existing body of knowledge on the topic and what further research is needed.
- Conclude the paper by summarizing the main findings, reiterating the significance of the research, and offering suggestions for future research.
Purpose of Research Results
The purposes of Research Results are as follows:
- Informing policy and practice: Research results can provide evidence-based information to inform policy decisions, such as in the fields of healthcare, education, and environmental regulation. They can also inform best practices in fields such as business, engineering, and social work.
- Addressing societal problems : Research results can be used to help address societal problems, such as reducing poverty, improving public health, and promoting social justice.
- Generating economic benefits : Research results can lead to the development of new products, services, and technologies that can create economic value and improve quality of life.
- Supporting academic and professional development : Research results can be used to support academic and professional development by providing opportunities for students, researchers, and practitioners to learn about new findings and methodologies in their field.
- Enhancing public understanding: Research results can help to educate the public about important issues and promote scientific literacy, leading to more informed decision-making and better public policy.
- Evaluating interventions: Research results can be used to evaluate the effectiveness of interventions, such as treatments, educational programs, and social policies. This can help to identify areas where improvements are needed and guide future interventions.
- Contributing to scientific progress: Research results can contribute to the advancement of science by providing new insights and discoveries that can lead to new theories, methods, and techniques.
- Informing decision-making : Research results can provide decision-makers with the information they need to make informed decisions. This can include decision-making at the individual, organizational, or governmental levels.
- Fostering collaboration : Research results can facilitate collaboration between researchers and practitioners, leading to new partnerships, interdisciplinary approaches, and innovative solutions to complex problems.
Advantages of Research Results
Some Advantages of Research Results are as follows:
- Improved decision-making: Research results can help inform decision-making in various fields, including medicine, business, and government. For example, research on the effectiveness of different treatments for a particular disease can help doctors make informed decisions about the best course of treatment for their patients.
- Innovation : Research results can lead to the development of new technologies, products, and services. For example, research on renewable energy sources can lead to the development of new and more efficient ways to harness renewable energy.
- Economic benefits: Research results can stimulate economic growth by providing new opportunities for businesses and entrepreneurs. For example, research on new materials or manufacturing techniques can lead to the development of new products and processes that can create new jobs and boost economic activity.
- Improved quality of life: Research results can contribute to improving the quality of life for individuals and society as a whole. For example, research on the causes of a particular disease can lead to the development of new treatments and cures, improving the health and well-being of millions of people.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Thesis Outline – Example, Template and Writing...

Research Paper Conclusion – Writing Guide and...

Appendices – Writing Guide, Types and Examples

How to Cite Research Paper – All Formats and...

Research Report – Example, Writing Guide and...

Delimitations in Research – Types, Examples and...
- Affiliate Program

- UNITED STATES
- 台灣 (TAIWAN)
- TÜRKIYE (TURKEY)
- Academic Editing Services
- - Research Paper
- - Journal Manuscript
- - Dissertation
- - College & University Assignments
- Admissions Editing Services
- - Application Essay
- - Personal Statement
- - Recommendation Letter
- - Cover Letter
- - CV/Resume
- Business Editing Services
- - Business Documents
- - Report & Brochure
- - Website & Blog
- Writer Editing Services
- - Script & Screenplay
- Our Editors
- Client Reviews
- Editing & Proofreading Prices
- Wordvice Points
- Partner Discount
- Plagiarism Checker
- APA Citation Generator
- MLA Citation Generator
- Chicago Citation Generator
- Vancouver Citation Generator
- - APA Style
- - MLA Style
- - Chicago Style
- - Vancouver Style
- Writing & Editing Guide
- Academic Resources
- Admissions Resources
How to Write a Discussion Section for a Research Paper
We’ve talked about several useful writing tips that authors should consider while drafting or editing their research papers. In particular, we’ve focused on figures and legends , as well as the Introduction , Methods , and Results . Now that we’ve addressed the more technical portions of your journal manuscript, let’s turn to the analytical segments of your research article. In this article, we’ll provide tips on how to write a strong Discussion section that best portrays the significance of your research contributions.
What is the Discussion section of a research paper?
In a nutshell, your Discussion fulfills the promise you made to readers in your Introduction . At the beginning of your paper, you tell us why we should care about your research. You then guide us through a series of intricate images and graphs that capture all the relevant data you collected during your research. We may be dazzled and impressed at first, but none of that matters if you deliver an anti-climactic conclusion in the Discussion section!
Are you feeling pressured? Don’t worry. To be honest, you will edit the Discussion section of your manuscript numerous times. After all, in as little as one to two paragraphs ( Nature ‘s suggestion based on their 3,000-word main body text limit), you have to explain how your research moves us from point A (issues you raise in the Introduction) to point B (our new understanding of these matters). You must also recommend how we might get to point C (i.e., identify what you think is the next direction for research in this field). That’s a lot to say in two paragraphs!
So, how do you do that? Let’s take a closer look.
What should I include in the Discussion section?
As we stated above, the goal of your Discussion section is to answer the questions you raise in your Introduction by using the results you collected during your research . The content you include in the Discussions segment should include the following information:
- Remind us why we should be interested in this research project.
- Describe the nature of the knowledge gap you were trying to fill using the results of your study.
- Don’t repeat your Introduction. Instead, focus on why this particular study was needed to fill the gap you noticed and why that gap needed filling in the first place.
- Mainly, you want to remind us of how your research will increase our knowledge base and inspire others to conduct further research.
- Clearly tell us what that piece of missing knowledge was.
- Answer each of the questions you asked in your Introduction and explain how your results support those conclusions.
- Make sure to factor in all results relevant to the questions (even if those results were not statistically significant).
- Focus on the significance of the most noteworthy results.
- If conflicting inferences can be drawn from your results, evaluate the merits of all of them.
- Don’t rehash what you said earlier in the Results section. Rather, discuss your findings in the context of answering your hypothesis. Instead of making statements like “[The first result] was this…,” say, “[The first result] suggests [conclusion].”
- Do your conclusions line up with existing literature?
- Discuss whether your findings agree with current knowledge and expectations.
- Keep in mind good persuasive argument skills, such as explaining the strengths of your arguments and highlighting the weaknesses of contrary opinions.
- If you discovered something unexpected, offer reasons. If your conclusions aren’t aligned with current literature, explain.
- Address any limitations of your study and how relevant they are to interpreting your results and validating your findings.
- Make sure to acknowledge any weaknesses in your conclusions and suggest room for further research concerning that aspect of your analysis.
- Make sure your suggestions aren’t ones that should have been conducted during your research! Doing so might raise questions about your initial research design and protocols.
- Similarly, maintain a critical but unapologetic tone. You want to instill confidence in your readers that you have thoroughly examined your results and have objectively assessed them in a way that would benefit the scientific community’s desire to expand our knowledge base.
- Recommend next steps.
- Your suggestions should inspire other researchers to conduct follow-up studies to build upon the knowledge you have shared with them.
- Keep the list short (no more than two).
How to Write the Discussion Section
The above list of what to include in the Discussion section gives an overall idea of what you need to focus on throughout the section. Below are some tips and general suggestions about the technical aspects of writing and organization that you might find useful as you draft or revise the contents we’ve outlined above.
Technical writing elements
- Embrace active voice because it eliminates the awkward phrasing and wordiness that accompanies passive voice.
- Use the present tense, which should also be employed in the Introduction.
- Sprinkle with first person pronouns if needed, but generally, avoid it. We want to focus on your findings.
- Maintain an objective and analytical tone.
Discussion section organization
- Keep the same flow across the Results, Methods, and Discussion sections.
- We develop a rhythm as we read and parallel structures facilitate our comprehension. When you organize information the same way in each of these related parts of your journal manuscript, we can quickly see how a certain result was interpreted and quickly verify the particular methods used to produce that result.
- Notice how using parallel structure will eliminate extra narration in the Discussion part since we can anticipate the flow of your ideas based on what we read in the Results segment. Reducing wordiness is important when you only have a few paragraphs to devote to the Discussion section!
- Within each subpart of a Discussion, the information should flow as follows: (A) conclusion first, (B) relevant results and how they relate to that conclusion and (C) relevant literature.
- End with a concise summary explaining the big-picture impact of your study on our understanding of the subject matter. At the beginning of your Discussion section, you stated why this particular study was needed to fill the gap you noticed and why that gap needed filling in the first place. Now, it is time to end with “how your research filled that gap.”
Discussion Part 1: Summarizing Key Findings
Begin the Discussion section by restating your statement of the problem and briefly summarizing the major results. Do not simply repeat your findings. Rather, try to create a concise statement of the main results that directly answer the central research question that you stated in the Introduction section . This content should not be longer than one paragraph in length.
Many researchers struggle with understanding the precise differences between a Discussion section and a Results section . The most important thing to remember here is that your Discussion section should subjectively evaluate the findings presented in the Results section, and in relatively the same order. Keep these sections distinct by making sure that you do not repeat the findings without providing an interpretation.
Phrase examples: Summarizing the results
- The findings indicate that …
- These results suggest a correlation between A and B …
- The data present here suggest that …
- An interpretation of the findings reveals a connection between…
Discussion Part 2: Interpreting the Findings
What do the results mean? It may seem obvious to you, but simply looking at the figures in the Results section will not necessarily convey to readers the importance of the findings in answering your research questions.
The exact structure of interpretations depends on the type of research being conducted. Here are some common approaches to interpreting data:
- Identifying correlations and relationships in the findings
- Explaining whether the results confirm or undermine your research hypothesis
- Giving the findings context within the history of similar research studies
- Discussing unexpected results and analyzing their significance to your study or general research
- Offering alternative explanations and arguing for your position
Organize the Discussion section around key arguments, themes, hypotheses, or research questions or problems. Again, make sure to follow the same order as you did in the Results section.
Discussion Part 3: Discussing the Implications
In addition to providing your own interpretations, show how your results fit into the wider scholarly literature you surveyed in the literature review section. This section is called the implications of the study . Show where and how these results fit into existing knowledge, what additional insights they contribute, and any possible consequences that might arise from this knowledge, both in the specific research topic and in the wider scientific domain.
Questions to ask yourself when dealing with potential implications:
- Do your findings fall in line with existing theories, or do they challenge these theories or findings? What new information do they contribute to the literature, if any? How exactly do these findings impact or conflict with existing theories or models?
- What are the practical implications on actual subjects or demographics?
- What are the methodological implications for similar studies conducted either in the past or future?
Your purpose in giving the implications is to spell out exactly what your study has contributed and why researchers and other readers should be interested.
Phrase examples: Discussing the implications of the research
- These results confirm the existing evidence in X studies…
- The results are not in line with the foregoing theory that…
- This experiment provides new insights into the connection between…
- These findings present a more nuanced understanding of…
- While previous studies have focused on X, these results demonstrate that Y.
Step 4: Acknowledging the limitations
All research has study limitations of one sort or another. Acknowledging limitations in methodology or approach helps strengthen your credibility as a researcher. Study limitations are not simply a list of mistakes made in the study. Rather, limitations help provide a more detailed picture of what can or cannot be concluded from your findings. In essence, they help temper and qualify the study implications you listed previously.
Study limitations can relate to research design, specific methodological or material choices, or unexpected issues that emerged while you conducted the research. Mention only those limitations directly relate to your research questions, and explain what impact these limitations had on how your study was conducted and the validity of any interpretations.
Possible types of study limitations:
- Insufficient sample size for statistical measurements
- Lack of previous research studies on the topic
- Methods/instruments/techniques used to collect the data
- Limited access to data
- Time constraints in properly preparing and executing the study
After discussing the study limitations, you can also stress that your results are still valid. Give some specific reasons why the limitations do not necessarily handicap your study or narrow its scope.
Phrase examples: Limitations sentence beginners
- “There may be some possible limitations in this study.”
- “The findings of this study have to be seen in light of some limitations.”
- “The first limitation is the…The second limitation concerns the…”
- “The empirical results reported herein should be considered in the light of some limitations.”
- “This research, however, is subject to several limitations.”
- “The primary limitation to the generalization of these results is…”
- “Nonetheless, these results must be interpreted with caution and a number of limitations should be borne in mind.”
Discussion Part 5: Giving Recommendations for Further Research
Based on your interpretation and discussion of the findings, your recommendations can include practical changes to the study or specific further research to be conducted to clarify the research questions. Recommendations are often listed in a separate Conclusion section , but often this is just the final paragraph of the Discussion section.
Suggestions for further research often stem directly from the limitations outlined. Rather than simply stating that “further research should be conducted,” provide concrete specifics for how future can help answer questions that your research could not.
Phrase examples: Recommendation sentence beginners
- Further research is needed to establish …
- There is abundant space for further progress in analyzing…
- A further study with more focus on X should be done to investigate…
- Further studies of X that account for these variables must be undertaken.
Consider Receiving Professional Language Editing
As you edit or draft your research manuscript, we hope that you implement these guidelines to produce a more effective Discussion section. And after completing your draft, don’t forget to submit your work to a professional proofreading and English editing service like Wordvice, including our manuscript editing service for paper editing , cover letter editing , SOP editing , and personal statement proofreading services. Language editors not only proofread and correct errors in grammar, punctuation, mechanics, and formatting but also improve terms and revise phrases so they read more naturally. Wordvice is an industry leader in providing high-quality revision for all types of academic documents.
For additional information about how to write a strong research paper, make sure to check out our full research writing series !
Wordvice Writing Resources
- How to Write a Research Paper Introduction
- Which Verb Tenses to Use in a Research Paper
- How to Write an Abstract for a Research Paper
- How to Write a Research Paper Title
- Useful Phrases for Academic Writing
- Common Transition Terms in Academic Papers
- Active and Passive Voice in Research Papers
- 100+ Verbs That Will Make Your Research Writing Amazing
- Tips for Paraphrasing in Research Papers
Additional Academic Resources
- Guide for Authors. (Elsevier)
- How to Write the Results Section of a Research Paper. (Bates College)
- Structure of a Research Paper. (University of Minnesota Biomedical Library)
- How to Choose a Target Journal (Springer)
- How to Write Figures and Tables (UNC Writing Center)

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- Advanced Search
- Journal List
- J Med Libr Assoc
- v.92(3); 2004 Jul
The introduction, methods, results, and discussion (IMRAD) structure: a fifty-year survey
Luciana b. sollaci.
1 William Enneking Library Sarah Network of Hospitals Brasilia, Federal District 70335-901 Brazil
Mauricio G. Pereira
2 University of Brasilia Department of Health Sciences Brasilia, Federal District 70919-900 Brazil
3 Catholic University of BrasiliaFaculty of MedicineBrasilia, Federal District 71966-700Brazil
Background: The scientific article in the health sciences evolved from the letter form and purely descriptive style in the seventeenth century to a very standardized structure in the twentieth century known as introduction, methods, results, and discussion (IMRAD). The pace in which this structure began to be used and when it became the most used standard of today's scientific discourse in the health sciences is not well established.
Purpose: The purpose of this study is to point out the period in time during which the IMRAD structure was definitively and widely adopted in medical scientific writing.
Methods: In a cross-sectional study, the frequency of articles written under the IMRAD structure was measured from 1935 to 1985 in a randomly selected sample of articles published in four leading journals in internal medicine: the British Medical Journal, JAMA, The Lancet, and the New England Journal of Medicine.
Results: The IMRAD structure, in those journals, began to be used in the 1940s. In the 1970s, it reached 80% and, in the 1980s, was the only pattern adopted in original papers.
Conclusions: Although recommended since the beginning of the twentieth century, the IMRAD structure was adopted as a majority only in the 1970s. The influence of other disciplines and the recommendations of editors are among the facts that contributed to authors adhering to it.
Since its origin in 1665, the scientific paper has been through many changes. Although during the first two centuries its form and style were not standardized, the letter form and the experimental report coexisted. The letter was usually single authored, written in a polite style, and addressed several subjects at the same time [ 1 ]. The experimental report was purely descriptive, and events were often presented in chronological order. It evolved to a more structured form in which methods and results were incipiently described and interpreted, while the letter form disappeared [ 2 ]. Method description increasingly developed during the second half of the nineteenth century [ 3 ], and an overall organization known as “theory—experiment—discussion” appeared [ 4 , 5 ]. In the early twentieth century, contemporary norms began to be standardized with a decreasing use of the literary style. Gradually, in the course of the twentieth century, the formal established introduction, methods, results, and discussion (IMRAD) structure was adopted [ 6 ].
However, neither the rate at which the use of this format increased nor the point at which it became the standard for today's medical scientific writing is well established. The main objective of this investigation is to discover when this format was definitively adopted. Also, to have a global idea of the articles published during the studied period, articles written without the IMRAD structure will be briefly described.
In a cross-sectional study, the frequency of articles using the IMRAD structure was measured at 5-year intervals, during the 50-year period from 1935 to 1985. Data collection began at 1960, moving forward and backward from that year until the frequency of IMRAD articles reached 100% and none respectively. A sample of 1 in every 10 issues of 4 leading medical journals in internal medicine was systematically selected to evaluate the articles published in these years. A total of 1,297 original articles—all those from each selected issue—were examined: 341 from the British Medical Journal, 328 from Journal of the American Medical Association (JAMA), 401 from The Lancet, and 227 from the New England Journal of Medicine. These journals were chosen based on their similarities in target audience, frequency, and lifespan. The journals had to be currently published at the beginning of the 20th century and show no interruptions during the studied period.
The criteria used by the journal for an original article were accepted. Therefore, if an article was labeled original by the journal, it was regarded as such, even though nowadays it might not be considered so. An article was considered to be written using the IMRAD structure only when the headings “methods, results, and discussion,” or synonyms for these headings, were all included and clearly printed. The introduction section had to be present but not necessarily accompanied by a heading. Articles that did not follow this structure were considered non-IMRAD. They could be generally grouped as: (1) continuous text, (2) articles that used headings other than the IMRAD, (3) case reports, and (4) articles that partially adopted the IMRAD structure.
One of the authors (Sollaci) collected the data. In a randomly selected subsample of forty-eight articles, the data collection was independently repeated after six months. A high agreement was found ( Kappa = 0.95; CI 95%:0.88; 1.0).
The frequency of articles written using the IMRAD structure increased over time. In 1935, no IMRAD article could be found. In 1950, the proportion of articles presented in this modern form surpassed 10% in all journals. Thereafter, a pronounced increase can be observed until the 1970s, when it reached over 80%. During the first 20 years, from 1935 to 1955, the pace of IMRAD increments was slow, from none to 20%. However, during the following 20 years, 1955 to 1975, the frequency of these articles more than quadrupled ( Figure 1 ).

Proportion of introduction, methods, results, and discussion (IMRAD) adoption in articles published in the British Medical Journal, JAMA, The Lancet, and the New England Journal of Medicine, 1935–1985 (n = 1,297)
All four journals presented a similar trend: the New England Journal of Medicine fully adopted the structure in 1975, followed by the British Medical Journal in 1980, and JAMA and The Lancet in 1985.
Regarding the non-IMRAD articles, the evolution and variations of text organization for all journals can be delineated. In the British Medical Journal and The Lancet, articles that used non-IMRAD headings prevailed from 1935 to 1945. A shift to articles that partially adopted the IMRAD structure occurred from 1950 to 1960. From 1965 and beyond, the full structure tends to predominate. Until 1960, texts with different headings and partial IMRAD headings shared the lead in JAMA. From 1965 onward, the complete format is the most used. The New England Journal of Medicine had a slightly different pattern. Until 1955, continuous text, non-IMRAD headings, and case reports predominated. After 1960, the IMRAD structure takes the lead.
As an example, Figure 2 shows the text organization in the British Medical Journal from 1935 to 1985. The ascending curve represents the IMRAD articles. It is the same as shown in Figure 1 , and the descending curves represent all other forms of text organization. A similar tendency was observed for The Lancet, JAMA, and the New England Journal of Medicine.

Text organization of published articles in the British Medical Journal from 1935 to 1985 (n = 341)
One interesting finding is that during the initial period of our study, the order of the IMRAD headings did not follow today's convention; results could be presented before methods or discussion before results, and, although a few articles followed the IMRAD structure in the 1940s, they were not the same as articles written with the IMRAD structure in the 1980s. Information, which today is highly standardized in one section, would be absent, repeated, or dispersed among sections in earlier articles.
Gradually and progressively, the IMRAD structure was adopted by the studied journals. Until 1945, articles were organized in a manner more similar to a book chapter, mainly with headings associated with the subject, and did not follow the IMRAD structure. From 1950 to 1960, the IMRAD structure was partially adopted, and, after 1965, it began to predominate, attaining absolute leadership in the 1980s.
The authors did not find definite reasons explaining the leadership of the IMRAD structure in the literature. It is possible that sciences other than medicine might have influenced the growing use of this structure. The field of physics, for example, had already adopted it extensively in the 1950s [ 7 ].
This structure was already considered the ideal outline for scientific writing in the first quarter of the 20th century [ 8 , 9 ]; however, it was not used by authors [ 10 ]. After World War II, international conferences on scientific publishing recommended this format [ 11 ], culminating with the guidelines set by the International Committee of Medical Journal Editors, formerly known as the Vancouver Group, first published in the late 1970s [ 12 ]. According to Huth [ 13 ], the wide use of the IMRAD structure may be largely credited to editors, who insisted on papers being clearly formatted to benefit readers and to facilitate the process of peer review.
According to Meadows [ 14 ], development and changes in the internal organization of the scientific article is simply an answer to the constant growth of information. The IMRAD structure facilitates modular reading, because readers usually do not read in a linear way but browse in each section of the article, looking for specific information, which is normally found in preestablished areas of the paper [ 15 ].
Four major leading journals of internal medicine were examined. It might be assumed that patterns set by these journals would be followed by others; nevertheless, caution should be taken in extrapolating these findings to other journals.
- Kronick D. A history of scientific and technical periodicals: the origins and development of the scientific and technical press 1665–1790. 2nd ed . Metuchen, NJ: Scarecrow, 1976. [ Google Scholar ]
- Atkinson D. Scientific discourse in sociohistorical context: the Philosophical Transactions of the Royal Society of London, 1675–1975 . Mahwah, NJ: Lawrence Erlbaum, 1999. [ Google Scholar ]
- Day RA. How to write & publish a scientific paper. 5th ed . Phoenix, AZ: Oryx, 1998. [ Google Scholar ]
- Atkinson D. The evolution of medical research writing from 1735 to 1985: the case of the Edinburgh Medical Journal . Applied Linguistics . 1992 Dec; 13 ( 4 ):337–74. [ Google Scholar ]
- Huth EJ. Structured abstracts for papers reporting clinical trials . Ann Internal Med . 1987 Apr; 106 ( 4 ):626–7. [ PubMed ] [ Google Scholar ]
- Bazerman C.. Modern evolution of the experimental report in physics: spectroscopic articles in Physical Review, 1893–1980. Social Studies of Science. 1984; 14 :163–96. [ Google Scholar ]
- Melish-Wilson MH. The writing of medical papers . Philadelphia, PA: WB Saunders, 1922. [ Google Scholar ]
- Trelease SF, Yule ES. Preparation of scientific and technical papers . Baltimore, MD: Williams & Wilkins, 1925. [ Google Scholar ]
- Council of Biology Editors Style Manual Committee. Scientific style and format: the CBE manual for authors, editors and publishers. 6th ed . Cambridge, UK: Cambridge University Press, 1994. [ Google Scholar ]
- Vickery B.. The Royal Society Scientific Conference of 1948. J Documentation. 1992; 54 (3):281–3. [ Google Scholar ]
- International Committee of Medical Journal Editors. Uniform requirements for manuscripts submitted to biomedical journals . Ann Internal Med . 1997 Jan 1; 126 ( 1 ):36–47. [ PubMed ] [ Google Scholar ]
- Meadows AJ. Communicating research . San Diego, CA: Academic Press, 1998. [ Google Scholar ]
- Meadows AJ.. The scientific paper as an archaeological artifact. J Inf Science. 1985; 11 (1):27–30. [ Google Scholar ]
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Dissertation
- How to Write a Discussion Section | Tips & Examples
How to Write a Discussion Section | Tips & Examples
Published on 21 August 2022 by Shona McCombes . Revised on 25 October 2022.

The discussion section is where you delve into the meaning, importance, and relevance of your results .
It should focus on explaining and evaluating what you found, showing how it relates to your literature review , and making an argument in support of your overall conclusion . It should not be a second results section .
There are different ways to write this section, but you can focus your writing around these key elements:
- Summary: A brief recap of your key results
- Interpretations: What do your results mean?
- Implications: Why do your results matter?
- Limitations: What can’t your results tell us?
- Recommendations: Avenues for further studies or analyses
Instantly correct all language mistakes in your text
Be assured that you'll submit flawless writing. Upload your document to correct all your mistakes.
Table of contents
What not to include in your discussion section, step 1: summarise your key findings, step 2: give your interpretations, step 3: discuss the implications, step 4: acknowledge the limitations, step 5: share your recommendations, discussion section example.
There are a few common mistakes to avoid when writing the discussion section of your paper.
- Don’t introduce new results: You should only discuss the data that you have already reported in your results section .
- Don’t make inflated claims: Avoid overinterpretation and speculation that isn’t directly supported by your data.
- Don’t undermine your research: The discussion of limitations should aim to strengthen your credibility, not emphasise weaknesses or failures.
Prevent plagiarism, run a free check.
Start this section by reiterating your research problem and concisely summarising your major findings. Don’t just repeat all the data you have already reported – aim for a clear statement of the overall result that directly answers your main research question . This should be no more than one paragraph.
Many students struggle with the differences between a discussion section and a results section . The crux of the matter is that your results sections should present your results, and your discussion section should subjectively evaluate them. Try not to blend elements of these two sections, in order to keep your paper sharp.
- The results indicate that …
- The study demonstrates a correlation between …
- This analysis supports the theory that …
- The data suggest that …
The meaning of your results may seem obvious to you, but it’s important to spell out their significance for your reader, showing exactly how they answer your research question.
The form of your interpretations will depend on the type of research, but some typical approaches to interpreting the data include:
- Identifying correlations , patterns, and relationships among the data
- Discussing whether the results met your expectations or supported your hypotheses
- Contextualising your findings within previous research and theory
- Explaining unexpected results and evaluating their significance
- Considering possible alternative explanations and making an argument for your position
You can organise your discussion around key themes, hypotheses, or research questions, following the same structure as your results section. Alternatively, you can also begin by highlighting the most significant or unexpected results.
- In line with the hypothesis …
- Contrary to the hypothesised association …
- The results contradict the claims of Smith (2007) that …
- The results might suggest that x . However, based on the findings of similar studies, a more plausible explanation is x .
As well as giving your own interpretations, make sure to relate your results back to the scholarly work that you surveyed in the literature review . The discussion should show how your findings fit with existing knowledge, what new insights they contribute, and what consequences they have for theory or practice.
Ask yourself these questions:
- Do your results support or challenge existing theories? If they support existing theories, what new information do they contribute? If they challenge existing theories, why do you think that is?
- Are there any practical implications?
Your overall aim is to show the reader exactly what your research has contributed, and why they should care.
- These results build on existing evidence of …
- The results do not fit with the theory that …
- The experiment provides a new insight into the relationship between …
- These results should be taken into account when considering how to …
- The data contribute a clearer understanding of …
- While previous research has focused on x , these results demonstrate that y .
Even the best research has its limitations. Acknowledging these is important to demonstrate your credibility. Limitations aren’t about listing your errors, but about providing an accurate picture of what can and cannot be concluded from your study.
Limitations might be due to your overall research design, specific methodological choices , or unanticipated obstacles that emerged during your research process.
Here are a few common possibilities:
- If your sample size was small or limited to a specific group of people, explain how generalisability is limited.
- If you encountered problems when gathering or analysing data, explain how these influenced the results.
- If there are potential confounding variables that you were unable to control, acknowledge the effect these may have had.
After noting the limitations, you can reiterate why the results are nonetheless valid for the purpose of answering your research question.
- The generalisability of the results is limited by …
- The reliability of these data is impacted by …
- Due to the lack of data on x , the results cannot confirm …
- The methodological choices were constrained by …
- It is beyond the scope of this study to …
Based on the discussion of your results, you can make recommendations for practical implementation or further research. Sometimes, the recommendations are saved for the conclusion .
Suggestions for further research can lead directly from the limitations. Don’t just state that more studies should be done – give concrete ideas for how future work can build on areas that your own research was unable to address.
- Further research is needed to establish …
- Future studies should take into account …
- Avenues for future research include …

Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
McCombes, S. (2022, October 25). How to Write a Discussion Section | Tips & Examples. Scribbr. Retrieved 12 March 2024, from https://www.scribbr.co.uk/thesis-dissertation/discussion/
Is this article helpful?

Shona McCombes
Other students also liked, how to write a results section | tips & examples, research paper appendix | example & templates, how to write a thesis or dissertation introduction.
We use cookies on this site to enhance your experience
By clicking any link on this page you are giving your consent for us to set cookies.
A link to reset your password has been sent to your email.
Back to login
We need additional information from you. Please complete your profile first before placing your order.
Thank you. payment completed., you will receive an email from us to confirm your registration, please click the link in the email to activate your account., there was error during payment, orcid profile found in public registry, download history, writing a compelling results and discussion section.
- Charlesworth Author Services
- 12 March, 2021
- Academic Writing Skills
In the results section of your academic paper, you present what you found when you conducted your analyses, whereas in your discussion section you explain what your results mean and connect them to prior research studies. In other words, the results section is where you describe what you did, and the discussion sections is where you describe what this means for the field.
The results section should include the findings of your study without any interpretations or implications that you can draw from those results. Here, you present the findings using text supported by tables, charts, graphs and other figures. For example, in the following excerpt from article by Tolksdorf, Crawshaw, & Rohlfing, (2021), you can see how directly they report the results of their study.
Contrary to our hypothesis, there was no main effect of time, F(3, ∞) = 0.638, p = 0.166, and no significant interaction between experimental condition and time, F(3, ∞) = 0.427, p = 0.133, indicating that no significant changes in children's social referencing behavior were found in either group over the entire course of the sessions, including all learning and test situations. However, there was a highly significant main effect of condition F(1, 16.99) = 49.08, p < 0.001, demonstrating that children in the human condition displayed social referencing significantly more often than their peers interacting with the robotic partner. (p. 6)
Further in the results section the authors use a table to illustrate their results.
Table 1 presents an overview of the different interactional contexts in which children’s social referencing was situated during the long-term interaction. (p. 6)

As you can see, the results section is very direct and reports the outcome from the statistical analyses conducted. Tables and figures can help break up this section, as it can be very technical. In addition, using visuals in this way makes the results more accessible to readers.
The discussion section, which follows the results section, will include an explanation of the results. In this section, you should connect your results to previous research studies, make explicit connections back to your research question(s) and include an explanation about how the results might be generalized. This is where you make an argument that supports your main conclusions. Unlike the results section, the discussion section is where you interpret your results and explain what they mean, draw implications from your results and articulate why they matter, discuss any limitations of your results, and provide recommendations that can be made from these results. The following excerpts from the Tolksdorf, Crawshaw, & Rohlfing, (2021), help to further illustrate the difference between the results and discussions sections.
Contrary to our prior assumption, we could not observe a significant decrease in children’s social referencing in both groups despite the repetition of the interaction and increasing familiarity with the situation. Whereas, there appeared to be a slight decreasing tendency from the second to the third learning situation in each group, this trend may have been slowed down by the subsequent novel situation of the retention task, which again increased children’s reliance on the caregiver despite increasing familiarity with the interaction partner. (p. 8)
The large difference in children’s social referencing behavior between an interaction with the human vs. robotic partner is striking. One explanation for our findings is that a human partner naturally responds to various social cues (Kahle and Argyle, 2014) from the child in ways that social robots are not yet capable of, given their present technological limitations. (p. 8)
Notice how the authors provide a critical analysis of their results and offer explanations for what they found. In the second excerpt, observe how they tie an explanation for their result to prior research conducted in the field. Focusing on the results and discussion sections of different articles, and highlighting language that differentiates these sections from each other, can really help you to write your academic papers effectively.
Although the length and structure of the discussion section across research papers varies, there are some commonalities in the structure and content of these sections. Below is a suggested outline for a discussion section.
Paragraph 1.
In this paragraph provide a broad overview of the importance of your study. This is where you should restate your research topic. Avoid just repeating what you included in the results section. Include the main research findings that answer your primary research question(s).
Paragraph 2–3.
This section should be a critical analysis of your major findings. Here, you should articulate your interpretations of those findings. You should include whether these were the findings you expected and also whether they support any hypothesis you had. Provide explanations for the significance of the results and for any unexpected findings. Link your primary findings back to prior research studies. This section would also include any implications of your results.
Paragraph 4.
Here you would include a discussion of any secondary findings that are of note. Additionally, you would also include any limitations of your study and how future studies might mitigate these limitations. The excerpt below, from the Tolksdorf, Crawshaw, & Rohlfing, (2021) study, provides an example of this.
We would also like to point to the possibility that the study design and procedure could have impacted our results. Adapting the design of the interaction from the robot experimental setting to be suitably comparable when taking place with a human interaction partner required us to make certain decisions. (p. 9)
Paragraph 5.
This should include the conclusion of the discussion section, and future directions. In this section you could include any new research questions that arose as a result of your study. Implications from your findings for the field should also be discussed in this paragraph.
There are a number of common errors researchers make when writing the results and discussion sections. The following checklist can help you avoid these common mistakes.
Do not include interpretations or explanations of the findings in your results section. Remember that in the results section you are telling the reader what you found and in the discussion section you are telling them what it means and why it matters.
Do not exclude negative findings from your results section. Although the temptation is to report only positive findings, negative findings are important to other researchers.
You should not introduce any findings in your discussion section that were not included in the results section. These two sections should align, and you should discuss and explain only what you have already reported.
Don’t restate results in the discussion paper without an explanation or critical analysis of what they mean and why they matter.
Don’t forget to go back and check that these two sections align, and the flow from the results section to the discussion section is smooth and clear.
Tolksdorf NF, Crawshaw CE and Rohlfing KJ (2021) Comparing the Effects of a Different Social Partner (Social Robot vs. Human) on Children's Social Referencing in Interaction. Front. Educ. 5:569615. doi: 10.3389/feduc.2020.569615
Charlesworth Author Services, a trusted brand supporting the world’s leading academic publishers, institutions and authors since 1928. We only work with native English-speaking editors with advanced or postdoctoral degrees in their disciplines.
To know more about our services: Link(https://www.cwauthors.com/EditingServices)
Our academic writing and publishing training courses, online materials, and blog articles contain numerous tips and tricks to help you navigate academic writing and publishing, and maximise your potential as a researcher.
Join us on our FREE series of webinars designed to help the researchers in achieving their publication success.
Register: (https://www.cwauthors.com/article/webinar-schedule-2020)
Maximise your publication success with Charlesworth Author Services.
Share with your colleagues
Recommended reading.

How to write an Introduction to an academic article
Charlesworth Author Services 17/08/2020 00:00:00
Related articles

Article Titles: The Do's and Don'ts
Charlesworth Author Services 25/04/2017 00:00:00

How do I present data in an academic article?

Getting the title of your research article right

How to write a Methods section in your research paper

Writing a strong Methods section
Charlesworth Author Services 12/03/2021 00:00:00

Writing an Abstract: Purpose and Tips
- Communicating in STEM Disciplines
- Features of Academic STEM Writing
- STEM Writing Tips
- Academic Integrity in STEM
- Strategies for Writing
- Science Writing Videos – YouTube Channel
- Educator Resources
- Lesson Plans, Activities and Assignments
- Strategies for Teaching Writing
- Grading Techniques
IMRAD (Introduction, Methods, Results and Discussion)
Academic research papers in STEM disciplines typically follow a well-defined I-M-R-A-D structure: Introduction, Methods, Results And Discussion (Wu, 2011). Although not included in the IMRAD name, these papers often include a Conclusion.
Introduction
The Introduction typically provides everything your reader needs to know in order to understand the scope and purpose of your research. This section should provide:
- Context for your research (for example, the nature and scope of your topic)
- A summary of how relevant scholars have approached your research topic to date, and a description of how your research makes a contribution to the scholarly conversation
- An argument or hypothesis that relates to the scholarly conversation
- A brief explanation of your methodological approach and a justification for this approach (in other words, a brief discussion of how you gather your data and why this is an appropriate choice for your contribution)
- The main conclusions of your paper (or the “so what”)
- A roadmap, or a brief description of how the rest of your paper proceeds
The Methods section describes exactly what you did to gather the data that you use in your paper. This should expand on the brief methodology discussion in the introduction and provide readers with enough detail to, if necessary, reproduce your experiment, design, or method for obtaining data; it should also help readers to anticipate your results. The more specific, the better! These details might include:
- An overview of the methodology at the beginning of the section
- A chronological description of what you did in the order you did it
- Descriptions of the materials used, the time taken, and the precise step-by-step process you followed
- An explanation of software used for statistical calculations (if necessary)
- Justifications for any choices or decisions made when designing your methods
Because the methods section describes what was done to gather data, there are two things to consider when writing. First, this section is usually written in the past tense (for example, we poured 250ml of distilled water into the 1000ml glass beaker). Second, this section should not be written as a set of instructions or commands but as descriptions of actions taken. This usually involves writing in the active voice (for example, we poured 250ml of distilled water into the 1000ml glass beaker), but some readers prefer the passive voice (for example, 250ml of distilled water was poured into the 1000ml beaker). It’s important to consider the audience when making this choice, so be sure to ask your instructor which they prefer.
The Results section outlines the data gathered through the methods described above and explains what the data show. This usually involves a combination of tables and/or figures and prose. In other words, the results section gives your reader context for interpreting the data. The results section usually includes:
- A presentation of the data obtained through the means described in the methods section in the form of tables and/or figures
- Statements that summarize or explain what the data show
- Highlights of the most important results
Tables should be as succinct as possible, including only vital information (often summarized) and figures should be easy to interpret and be visually engaging. When adding your written explanation to accompany these visual aids, try to refer your readers to these in such a way that they provide an additional descriptive element, rather than simply telling people to look at them. This can be especially helpful for readers who find it hard to see patterns in data.
The Discussion section explains why the results described in the previous section are meaningful in relation to previous scholarly work and the specific research question your paper explores. This section usually includes:
- Engagement with sources that are relevant to your work (you should compare and contrast your results to those of similar researchers)
- An explanation of the results that you found, and why these results are important and/or interesting
Some papers have separate Results and Discussion sections, while others combine them into one section, Results and Discussion. There are benefits to both. By presenting these as separate sections, you’re able to discuss all of your results before moving onto the implications. By presenting these as one section, you’re able to discuss specific results and move onto their significance before introducing another set of results.
The Conclusion section of a paper should include a brief summary of the main ideas or key takeaways of the paper and their implications for future research. This section usually includes:
- A brief overview of the main claims and/or key ideas put forth in the paper
- A brief discussion of potential limitations of the study (if relevant)
- Some suggestions for future research (these should be clearly related to the content of your paper)
Sample Research Article
Resource Download
Wu, Jianguo. “Improving the writing of research papers: IMRAD and beyond.” Landscape Ecology 26, no. 10 (November 2011): 1345–1349. http://dx.doi.org/10.1007/s10980-011-9674-3.
Further reading:
- Organization of a Research Paper: The IMRAD Format by P. K. Ramachandran Nair and Vimala D. Nair
- George Mason University Writing Centre’s guide on Writing a Scientific Research Report (IMRAD)
- University of Wisconsin Writing Centre’s guide on Formatting Science Reports

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Results & Discussion
Characteristics of results & discussion.
- Results section contains data collected by scientists from experiments that they conducted.
- Data can be measurements, numbers, descriptions and/or observations.
- Scientific data is typically described using graphs, tables, figures, diagrams, maps, charts, photographs and/or equations.
- Discussion section provides an interpretation of the data, especially in context to previously published research.
The Results and Discussion sections can be written as separate sections (as shown in Fig. 2 ), but are often combined in a poster into one section called Results and Discussion. This is done in order to (1) save precious space on a poster for the many pieces of information that a scientist would like to tell their audience and (2) by combining the two sections, it becomes easier for the audience to understand the significance of the research. Combining the Results section and Discussion section in a poster is different for what is typically done for a scientific journal article. In most journal articles, the Results section is separated from the Discussion section. Journal articles are different from posters in that a scientist is not standing next to their journal article explaining it to a reader. Therefore, in a journal article, an author needs to provide more detailed information so that the reader can understand the research independently. Separating the Results section and Discussion section allows an author the space necessary to write a lengthier description of the research. Journal articles typically contain more text and more content (e.g., figures, tables) than posters.
The Results and Discussion section should contain data, typically in the form of a graph, histogram, chart, image, color-coded map or table ( Figs. 1 & 4 ). Very often data means numbers that scientists collect from making measurements. These data are typically presented to an audience in the form of graphs and charts to show a reader how these numbers change over time, space or experimental conditions ( Fig. 7 ). Numbers can increase, decrease or stay the same and a graph, or another type of figure, can be effectively used to convey this information to a reader in a visual format ( Fig. 7 ).
Figure 7. Example of a Graph

An audience will be attracted to a poster because of its figures and so it is very important for the author to pay particular attention to the creation, design and placement of the figures in a poster ( Figs. 1 & 4 ). A good figure is one that is informative, easy to comprehend and allows the reader to understand the significance of the data and experiment. Very often an author will use color to draw attention to a figure.
The Discussion section should state the importance of the research that is presented in the poster. It should provide an interpretation of the results, especially in context to previously published research. It may propose future experiments that need to be conducted as a result of the research presented in the poster. It should clearly illustrate the significance of the research with regards to new knowledge, understanding and/or discoveries that were made as part of the research.
Scientific Posters: A Learner's Guide Copyright © 2020 by Ella Weaver; Kylienne A. Shaul; Henry Griffy; and Brian H. Lower is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Share This Book
- Open access
- Published: 15 March 2024
Can the Reboot coaching programme support critical care nurses in coping with stressful clinical events? A mixed-methods evaluation assessing resilience, burnout, depression and turnover intentions
- K. S. Vogt 1 , 2 , 8 ,
- J. Johnson 1 , 2 , 3 ,
- R. Coleman 1 , 7 ,
- R. Simms-Ellis 1 , 2 ,
- R. Harrison 3 , 4 ,
- N. Shearman 5 , 11 ,
- J. Marran 1 ,
- L. Budworth 1 , 6 , 10 ,
- C. Horsfield 9 ,
- R. Lawton 1 , 2 &
- A. Grange 1
BMC Health Services Research volume 24 , Article number: 343 ( 2024 ) Cite this article
Metrics details
Critical care nurses (CCNs) are routinely exposed to highly stressful situations, and at high-risk of suffering from work-related stress and developing burnout. Thus, supporting CCN wellbeing is crucial. One approach for delivering this support is by preparing CCNs for situations they may encounter, drawing on evidence-based techniques to strengthen psychological coping strategies. The current study tailored a Resilience-boosting psychological coaching programme [Reboot] to CCNs. Other healthcare staff receiving Reboot have reported improvements in confidence in coping with stressful clinical events and increased psychological resilience. The current study tailored Reboot for online, remote delivery to CCNs (as it had not previously been delivered to nurses, or in remote format), to (1) assess the feasibility of delivering Reboot remotely, and to (2) provide a preliminary assessment of whether Reboot could increase resilience, confidence in coping with adverse events and burnout.
A single-arm mixed-methods (questionnaires, interviews) before-after feasibility study design was used. Feasibility was measured via demand, recruitment, and retention (recruitment goal: 80 CCNs, retention goal: 70% of recruited CCNs). Potential efficacy was measured via questionnaires at five timepoints; measures included confidence in coping with adverse events (Confidence scale), Resilience (Brief Resilience Scale), depression (PHQ-9) and burnout (Oldenburg-Burnout-Inventory). Intention to leave (current role, nursing more generally) was measured post-intervention. Interviews were analysed using Reflexive Thematic Analysis.
Results suggest that delivering Reboot remotely is feasible and acceptable. Seventy-seven nurses were recruited, 81% of whom completed the 8-week intervention. Thus, the retention rate was over 10% higher than the target. Regarding preliminary efficacy, follow-up measures showed significant increases in resilience, confidence in coping with adverse events and reductions in depression, burnout, and intention to leave. Qualitative analysis suggested that CCNs found the psychological techniques helpful and particularly valued practical exercises that could be translated into everyday practice.
This study demonstrates the feasibility of remote delivery of Reboot and potential efficacy for CCNs. Results are limited due to the single-arm feasibility design; thus, a larger trial with a control group is needed.
Peer Review reports
The healthcare professions are seen as some of the most stressful occupations, due to the close human contact, involvement with illness, death and dying, quick decision-making, risk of making errors and the involvement in adverse events they entail [ 1 , 2 , 3 , 4 , 5 , 6 ]. This stress and the demands on health care professionals (HCPs) have been exacerbated by the Covid-19 pandemic. Over the past 3 years, HCPs have had to cope with extreme emotional and physical stress, which has included redeployment, insufficient provision of medical supplies and personal protective equipment (PPE) and witnessing a record number of deaths among patients and colleagues. They have also been under pressure to adhere to ever-evolving infection control measures and have experienced anxiety about their personal health (as well as that of their families) [ 7 , 8 , 9 , 10 , 11 , 12 , 13 , 14 , 15 , 16 ]. Out of all areas of healthcare, Critical Care has been the most significantly affected clinical area by Covid-19 [ 17 , 18 , 19 ]. This has had detrimental effects to the psychological wellbeing of staff working in critical care units and is especially true for critical care nurses (CCNs) [ 19 , 20 , 21 , 22 , 23 , 24 , 25 , 26 ].
The international literature has consistently identified CCNs as having the worst outcomes on psychological wellbeing measures, such as depression, burnout, and post- traumatic stress disorder (PTSD) both during, and since the pandemic, and both compared to other critical care HCPs, such as physicians, and compared to non-critical care HCPs [ 21 ]. Two studies that illustrate the impact of working as a critical care nurse during the pandemic were conducted by Greenberg et al. [ 22 ] and Moll et al. [ 21 ]. In the United Kingdom (UK), Greenberg et al. surveyed 709 HCPs working in Critical Care on nine intensive care units (ICUs). Out of the three groups (doctors, nurses and ‘other’ ), CCNs ( n = 344; 49% of the sample) were significantly more likely to screen positive for depression (moderate, and severe), PTSD and anxiety (moderate, and severe). Further,19% of these nurses reported suicidal ideation [ 21 ]. In the US, Moll et al. compared the burnout scores of healthcare professionals working on critical care units between 2017 ( n = 572, nurses n = 323) and 2020 ( n = 710, nurses n = 372). Nurses were found to have the sharpest increase in burnout, despite increases in burnout across all professions surveyed. Taken together, these findings show that CCN wellbeing has been significantly impacted by the pandemic. Therefore, it essential that HCPs are supported in their wellbeing, and that they can draw on evidence-based techniques to recover from stressful events, without suffering negative psychological consequences.
Furthermore, poor CCNs wellbeing, the development of burnout and PTSD have been linked with intention to leave critical care nursing, and nursing altogether [ 15 , 23 , 27 , 28 , 29 ]. Thus, supporting CCNs’ wellbeing is not only a priority at an individual level (for individual CCNs), but must also be a priority at organizational level, to avoid further staff shortages [ 20 ]. One of the protective factors against the development of PTSD and burnout is psychological resilience [ 30 , 31 , 32 , 33 ]. Resilience refers to someone’s ability to maintain an emotional equilibrium during difficult experiences [ 34 ]. There is now increasing evidence that resilience can be increased with the help of psychological interventions [ 35 , 36 ]. The Recovery-boosting [“Reboot”] coaching programme evaluated in the current study seeks to enhance HCP resilience by providing them with evidence-based psychological tools to prepare and recover from stressful clinical events. Reboot aims to develop psychological constructs known to confer resilience, including higher self-esteem, greater mental flexibility, and a more positive explanatory style for negative events [ 19 , 37 , 38 ]. Reboot was first developed and piloted in 66 HCPs and healthcare students; groups included paediatric doctors, midwives, and physician associate students [ 37 ]. It consisted of one 4-hour workshop and one 1-hour coaching phone call. At follow-up, participants showed significantly higher levels of psychological resilience and confidence in coping with adverse events; suggesting the intervention was feasible and acceptable to participants and potentially effective for increasing resilience. Although these results were promising, nurses were not included in the study [ 37 ]. Therefore, the feasibility of Reboot for nurses remains to be established through further research [ 19 ].
The COVID-19 pandemic generated an increased need for psychological support for nurses, particularly CCNs, given their significant distress and worse psychological outcomes than other critical care professionals [ 22 , 25 ]. However, the pandemic also drastically reduced the feasibility of delivering in-person psychological interventions. Thus, the current study aimed to adapt the pre-existing Reboot programme for remote delivery for CCNs [ 19 ].
The primary objective was to assess the feasibility of delivering Reboot via online, remote delivery to CCNs. This was measured via demand, recruitment, and programme retention statistics.
The secondary objective was to provide a preliminary assessment of whether Reboot was associated with increases in self-reported psychological resilience and confidence in coping with adverse events, and decreases in depression and burnout, via analysis of questionnaires and interviews.
A more detailed report of the methods can be found in the open-access study protocol paper [ 19 ].
Study design & settings
A single-arm before-after feasibility study design was used; with a mixed-methods evaluation. Participants were invited to complete online questionnaires at five time points, which were Baseline (Time 1), following completion of two group workshops (Time 2), following completion of two individual coaching calls (Time 3), at 2-week follow-up post the final coaching call (Time 4). A fifth timepoint (Time 5) was added in May 2022 to investigate participants’ intention to leave nursing.
Online interviews were conducted with 25% of participants [who were randomly selected], after completion of the intervention. The Kirkpatrick model for assessing training interventions [ 39 ] was used, and four levels of outcome data were collected (Reaction, Learning, Behaviour, Results), as per Johnson et al. [ 37 ].
Ethics approval
Ethics approval was granted by the School of Psychology, University of Leeds Ethics committee (approved on 25-08-2021, PSYC-302; an ethics amendment was approved on 09-05-2022, PSYC-535). The study adheres to both the British Psychological Society’s Code of Ethics and Conduct, as well as Declaration of Helsinki.
Adaptation to online, remote delivery
Reboot was adapted for online delivery from a previous in-person group delivery method. This is reported in-depth in the study protocol [ 19 ]. The original intervention consisted of one 4-hour in-person group workshop and one 1-hour individual coaching phone call; and was delivered by a Clinical Psychologist (JJ) and an Occupational Health Psychologist (RSE) [ 37 ]. Adaptation for online, remote delivery involved changing this to two 2-hour online group workshops hosted via Zoom (each pair of workshops was termed a ‘cycle’), and two 1-hour individual coaching calls and was delivered by a Cognitive-behavioural (CBT) therapist (RC).
Participants
The recruitment target was 80 CCNs working in the National Health Service (NHS) in the UK. Full inclusion/exclusion criteria, and sample size justification can be found in the protocol paper [ 19 ].
Primary feasibility outcomes
As per protocol, feasibility outcomes were measured via demand [how many CCNs signed up], recruitment [how many CCNs consented and attended the first workshop], and retention [a) how many participants completed both workshops, b) how many participants completed both workshops and coaching calls, and c) how many completed the final follow-up questionnaires]. Using results of the in-person version of Reboot delivered by, feasibility success for the current study was met, if the following criteria were met:
at least 80 CCNs signed up to the study (demand)
at least 80 CCNs consented to taking part in the study and attend the first workshop (recruitment).
at least 90% of recruited CCNs complete both workshops
at least 70% completed both workshops and coaching calls, and
at least 50% of recruited CCNs complete all follow-up measures, up to Time 4.
Secondary outcomes
Secondary outcomes were resilience [measured via the Brief Resilience Scale (BRS)] [ 40 ]], confidence in coping with adverse events [measured via Confidence in Coping with Adverse Events Questionnaire [ 37 ]] , knowledge of resilience [measured via Knowledge Assessment [ 37 ] , Burnout [ measured via an abbreviated version of the Oldenburg Burnout Inventory (OLBI) [ 41 ]], and depression [measured via the Patient Health Questionnaire (PHQ-9) [ 42 ]]. Feedback and reactions to the Reboot workshops [assessed via “Feedback” questionnaire [ 37 ] were also assessed. Internal reliability coefficients for the measures are reported in the ‘ Results ’ section of this paper.
- Intention to leave
In addition to the above outcomes, an amendment was made to the original protocol to include a measure of intention to leave. All participants who completed the programme (both workshops, both coaching calls) were asked to answer an extra questionnaire as part of an additional follow-up survey. Participants were firstly asked to answer a set of questions measuring their turnover intentions as they recalled them prior to participating in Reboot (“ Think back to two weeks before you attended your first Reboot workshop, how were you feeling …?” and then a set of questions about their current turnover intentions (“How are you feeling now …?”). More specifically, intention to leave was measured via three items for the two time points (“I was/am planning to leave critical care nursing for another type of nursing”, “ I was/am planning to leave nursing altogether” and “ I was/am planning to continue working as a critical care nurse ” [reverse coded]) and answered on a scale from Strongly agree (1) to strongly disagree (5), with lower scores indicating lower intention to leave in critical care nursing.
Study information was circulated to the CCNs via Critical Care Networks and social media, via flyers, tweets, websites, and emails. A QR code could be used to access a website containing study information and a sign-up link. During sign-up, participants provided their details, and selected dates for workshops 1 and 2 from a list of cycles. Confirmation of dates was confirmed by email. Seven days prior to workshop 1, participants received an email with a questionnaire link, containing 1) consent form, 2) baseline survey, 3) a video to watch prior to attending the first workshop and 4) online links to access their workshops. Around the same time, participants also received a booklet in the post to use in the workshops, as well as a welcome phone call from the therapist facilitating the workshops. Both workshops took place via Zoom. At the end of the second workshop, the therapist asked participants to complete the Time-2 questionnaire and booked participants in for their two coaching calls. The coaching calls took place via phone or video call, depending on preference. After coaching call 2, participants completed Time-3 questionnaires, which they were sent by the therapist. Two to three weeks after the second coaching call, participants were emailed Time-4 questionnaires, and were invited to take part in an interview if selected (see Appendix 1 for Interview Guide). Interviewees were selected via random number generation from 0 to 100, numbers were assigned to participants in order of sign-up.
In May 2022, participants received a further questionnaire, assessing intention to leave critical care nursing. This questionnaire was an amendment to the protocol. This was added due to several stakeholder groups and the research literature indicating that measures of intention to leave are paramount to evaluation and implementation of interventions, and especially salient considering the current international healthcare workforce crisis. The questionnaire was distributed via email to all 62 nurses who completed the whole programme (thus, both workshops and both coaching calls). A £5 voucher was offered to all as an incentive to participate.
Analysis plan
Quantitative analyses.
A more detailed report of the analysis can be found in the study protocol paper [ 19 ]. Data were analysed with both R and SPSS. Multilevel (random intercepts for participants) regression models for each outcome included a timepoint coefficient, and were unadjusted, or sequentially adjusted for gender, age, and experience (years in profession). Holm-corrected t- tests further assessed between timepoint differences in outcomes.
Qualitative analyses
As per protocol, reflexive thematic analysis (RTA) [ 43 ] was used to analyse the interviews. RTA does not require a pre-determined ontological or epistemological framework; and is therefore commonly used in applied health research. KSV coded all interviews; and RSE coded a subset of these [ n = 3, 20%]. Similarities and differences in coding was discussed between the researchers; however, the researchers generally agreed on the use of codes and salient aspects to code.
Participant characteristics
A total of 84 participants consented to participate in the study. Most participants were female [86%], and their mean age was 39.7 [SD = 9.2; range: 22-60; missing n = 3]. Participants’ years of experience as registered nurses ranged from 0 [i.e., less than 1 year’s experience] to 39, with a mean of 13.9 [SD = 9.0, missing n = 3]; while their years of experience as registered nurses in critical care ranged from 0 to 35, with a mean of 10.7 [SD = 8.8, missing n = 3]. Three CCNs indicated that they were off work with stress when they completed the baseline questionnaire; however, when/if those nurses return to work was not followed up. At baseline, two CCNs were also taking part in other workplace wellbeing initiatives, and four others indicated that they had taken part in workplace wellbeing initiatives in the past. Fifteen interviews were conducted by KV (24% of participants), one of which was a pilot interview to trial the interview schedule, so is not included in the analysis.
Intervention delivery
Twenty-five workshop cycles were offered to participants. Nineteen cycles were chosen by participants, 6 cycles were cancelled and participant numbers in each ranged from two to six participants.
A total of 102 UK CCNs signed-up to the study by booking a place; thus, the target of recruiting at least 80 CCNs was met.
Recruitment
A total of 84 CCNs consented to participate in the study. Out of the 84, 77 attended the first workshop [91.7%], thus the objective of recruiting at least 80 CCNs was not met, but this was within 5% of the goal figure.
Programme retention: online, remote delivery of reboot
Of the 102 sign-ups, there were 62 completions, 15 dropped-out during the programme and 25 signed up but did not attend or cancelled their first workshop. Out of the 77 who attended the first workshop, 62 completed both workshops and both coaching calls; thus, 80.5% of those who attended the first workshop completed the programme – this means that the objective of achieving a (participation) retention rate of ≥70% was met.
Retention: feasibility of evaluation of online, remote delivery of reboot
Out of the 77 who completed the first workshop, 58.4% completed final, time-4 measures. Thus, the objective of ≥50% completion rates for the final follow-up questionnaire was met.
The secondary objective was to provide a preliminary assessment of whether Reboot could potentially significantly increase both self-reported psychological resilience and confidence in coping with adverse events, via analysis of questionnaires and interviews.
Quantitative results
Descriptive statistics are presented in Tables 1 , 2 and 3 ; and model-fit and results are presented in Tables 4 and 5 (4 for unadjusted models, 5 for adjusted models). All analyses indicated considerable clustering, supporting the use of random intercepts. The proportion of variance explained by all indicator variables was sizeable across measures, however, a higher proportion of variance was explained by fixed time points explained plus random effects. Adjusting the model for gender, age and experience did not alter model fit, thus are not reported here but results can be viewed in Table 4 .
Confidence scores increased significantly, compared to pre-intervention (Time 1) [Time 2: unadjusted β = 0.80, CI: 0.66 - 0.94, p < .001, d = .81; Time 3: unadjusted R 2 = 0.75, CI: 0.59 - 0.91, p < .001, d = 0.78; Time 4: unadjusted R 2 = 0.85, CI: 0.68 - 1.01, p < .001, d = 0.80]. Post-hoc t-tests comparing timepoint means showed no further increase in confidence when comparing between T2, T3 and T4, indicating that initial increases were maintained and remained stable [range p holm .977; adjusted for multiple comparisons]. Cronbach’s α for the confidence measure ranged from 0.64 - 0.87 across timepoints.
Knowledge scores increased significantly between Time 1 and Time 2 [unadjusted β = 0.48, CI: 0.16-0.30, p < .001, d = 0.79].
Descriptive statistic present sums of items, whereas models used the mean of items.
Resilience scores increased significantly between Time 1 and Time 3 [unadjusted β = 0.39, CI: 0.23 - 0.56, p < .001, d = 0.43] as well as between Time 1 and Time 4 [unadjusted β = 0.42, CI: 0.26 - 0.59, p < .001, d = 0.49]. Post-hoc tests comparing timepoint means indicated that there was no further increase in resilience between Time 3 and Time 4 ( p holm = .75), suggesting that initial gains remained stable. Cronbach’s alpha for the three time points it was used at, was between .80-.83; thus indicating good reliability.
Burnout scores decreased significantly between Time 1 and Time 3 [unadjusted β = −.037, CI: − 0.50- (− 0.25), p < .001, d = − 0.51 and between Time 1 and Time 4 [unadjusted β = −.039, CI-0.52 – (− 0.26), p < .001, d = − 0.56]. Post-hoc tests showed no significant difference was found on the BRS between T2 and T4; p holm = .82, indicating that decreases were maintained and remained stable. Reliability for the questionnaire was good, with Cronbach’s alpha ranging from .76-.84 for the three time points.
Scores on the PHQ-9 indicated a significant decrease in depression from both Time 1 to Time 3 [unadjusted β = −.045, CI: − 0.59 – - 0.32, p < .001 as well as from Time 1 to Time 4 [unadjusted β = −.048, CI: − 0.6 – (− 0.35); p < .001].
Post-hoc tests showed no significant difference on PHQ-9 scores between T3 and T4; p holm = .73, indicating that reductions were maintained and remained stable. Cronbach’s alpha for the PHQ-9 for the three time points it was used ranged from .83-.88, thus indicating good reliability. Out of the 39 participants who completed the PHQ-9 at both baseline and Time 4, almost 80% of participants screened for the presence of mild or severe depression at baseline (PHQ-9 score of 4 or above), whereas at Time 4, only 31.8% did.
Feedback/reactions
Feedback and reactions to the Reboot workshop were overwhelmingly positive (Tables 2 and 3 ). Most participants agreed or strongly agreed that it was relevant for their professional group; they learned useful skills and felt the workshops were adequate in length and were engaging. The majority also indicated that they would react differently if they were involved in a stressful workplace event after attending the workshop. Only a minority ( n = 5) indicated that there were aspects of the workshops that they did not find useful. Seventy-two CCNs answered the question as to whether they would recommend the workshops to other HCPs; 71 indicated that yes, they would, whereas one participant said they would not.
Thirty-two out of the 62 nurses who completed the full programme responded to the invitation to complete an additional questionnaire in May 2022 (response rate: 51.6%). Participants were asked to answer a set of questions measuring their turnover intentions as they recalled them prior to participating in Reboot (pre-Reboot), and as they are now (post-Reboot). Higher scores indicate lower intention to leave. Using a paired-samples t-test, a significant difference in intention to leave between pre-Reboot (mean = 11.50, SD =2.64) to post-Reboot (mean = 13.56, SD = 1.63) was found [t (31) = 4.93, p < .001, d = 0.94], showing that nurses reported significantly lower intention to leave critical care nursing after completing the programme than before. Cronbach’s α for post-Reboot was 0.73 and 0.78. for pre-Reboot.
Qualitative results
From the 15 interviews, two themes were developed. These were: “The value and impact of Reboot for participants and beyond ” and “Online delivery and content”. Both themes had subthemes, illustrated in Fig. 1 .

Graphic representation of qualitative findings
Theme 1: the value and impact of reboot for participants and beyond
The value and impact of Reboot was described as “priceless ” (Interview 14) for participants themselves, for their peers with whom they were able to share the psychological tools and knowledge with, and for organisations.
The value and impact of reboot for participants
Specific benefits that participants identified for themselves as a result of attending Reboot were better understanding of their own thought processes and emotions, better understanding of why errors happen at work, having a “ tool kit ” (Interview 15) of simple, psychological tools that they can draw on in times of stress (both at work and outside of work), being able to better manage mental and physical stress, and being able to better compartmentalise work and life outside of work.
Participants also specifically identified increases in wellbeing, confidence and knowledge about resilience, and decreases in burnout and intention to leave (Table 6 ). In addition, CCNs expressed that the group workshops made them feel validated in their feelings of stress, and that it was helpful to meet other professionals outside of their organisation who had similar experiences:
“… but actually speaking to other people who'd been through a similar experience, who they wish they'd done some things differently as well you know… made you kind of realize we are human, we tried our best and hindsight is a wonderful thing, and experience is a wonderful thing…” (Interview 4)
The value and impact of reboot for peers of participants
Five participants, who were predominantly senior CCNs, also expressed that after Reboot, they were “ also able now to help other people bounce back “(Interview 14) by sharing knowledge and tools learnt during Reboot.
“I was sat with them one of my nurses who, who thought they'd made an error. I'm not sure they did but they were being really hard on themselves, they were ruminating and going over and over and over, to a really unhealthy extent. So, I brought in some of what we've done at the workshop, and I said you know this is what you're doing and it's not healthy and these are ways that you can you know, you need to try and break the cycle.” (Interview 4)
The value and impact of reboot for organisations
Being offered training around psychological tools to cope with stress and how to boost resilience was described as essential by CCNs, as otherwise they would not be able to do their jobs. Thus, CCNs drew links between accessing programs like Reboot and the sustainability of the workforce in critical care.
“I'm sure that it will give me the staying power because things are going - always going to come up at work I think that are challenging” (Interview 13)
“you've got to have a lot of resilience to be able to even want to turn up ” (Interview 2)
All participants said that Reboot should be offered to nurses early on in their nursing career, especially within the first year of working in critical care.
“everybody else had ought to be going” (Interview 7)
“I think really early on in their career, to be able… to know how to approach negative thinking habits… to stop the rumination;… the amount of time I have ruminated on situations and blamed myself for things… they really do play on your mind for weeks sometimes. I think having these tools, so just to have them really early on in your career, so you know how to, how to approach those situations…” (Interview 15)
One participant suggested that while the value of Reboot lay in its focus on the acute, stressful situations that occur in intensive care settings, it does not address more long-term problems, such as issues with turnover and short staffing which are also affecting staff wellbeing.
“I think it's a bit more difficult with everything that's happening due to Covid and staffing at the moment with us, because we've got a lot of turnover of staff because, I guess, people just aren’t happy, but in acute situations, definitely.” (Interview 2)
Theme 2: online delivery and content
This theme incorporates narratives around the delivery and content of the workshops, coaching calls and suggestions for improvement.
Delivery and content of the workshops
Participants spoke positively about the online delivery of Reboot. The workshops were perceived as “ delivered at the right pitch” (Interview 14) and “comfortable ” (Interview 4), with no problems with internet connectivity. Participants liked the presented background to the interventions, the opportunity to share their experiences with other CCNs and the practical content of the workshops. Some participants commented on the fact that the ‘ homework’ set between the first and second workshop was helpful as it made them more conscious of what they were doing and feeling. Participants liked having the workbook to accompany the sessions, and to have as a point of reference for the future.
‘I liked the activities that you did and it was quite personal to you, so you could bring your own experiences, and use them and we went through them, shared with each person how you could use strategies to help you. That was good as well.” -Interview 2
“Really enjoyed and it was very active, not like one speaker is speaking and someone else just listening in - no, really, everything was really practical, in a realistic way… It was really a natural, realistic knowledgeable feeling.” - Interview 11
Delivery and content of the coaching calls
The coaching calls following the workshops were described as deepening understanding, empowering, helpful, professional, and relaxed. Participants spoke very highly of the CBT therapist delivering the intervention, praising their kindness and helpfulness. CCNs felt understood, and appreciated the individualised support, which often included specific materials being sent to them by email following the coaching calls.
“they [the coaching calls] were probably the most helpful” -Interview 2
“Touched in every corner… whenever I got a doubt, I was suddenly sharing with [therapist name] and she was listening and giving some kind of tools and… it was really touching it.” – Interview 11
“I thought, I thought she was brilliant… and really kind, and she listened… I was really thankful.” – Interview 13
One of the participants described the coaching calls as “ invaluable ” (Interview 14) and liked the fact that the coaching calls gave her opportunity to discuss what she was struggling with and tools to solve the problems for herself, with support of the therapist, rather than being given a solution to a problem.
“Quite invaluable and as a supported tool… because it wasn't like, …“this this is the problem… okay well, here's the answer”, it wasn’t that.. it was a “right, well that is the problem, let’s look at some tools you can use to help and support you to find a way through that yourself”, which was really empowering…. It's not sort of… “this the problem I had…this is how you fix it… this is what you've got to do. It wasn't that - it's “here's some tools, work through those tools, see what you think when we come back on the next coaching call” … very empowering, so I had to sit there and do that myself, which was great.” – Interview 14
Suggestions and recommendations
Participants made a small number of suggestions to improve Reboot, which included a slightly longer workbook with more content, to ensure that content is not forgotten about, more coaching calls and delivering some ‘refreshers’ on content later on. One participant also suggested including an example about long-term stressors, such as sustained short staffing.
Unlike with the workshops, participants did not receive reminders about their coaching calls from the research team or therapist, which meant that some participants forgot they had booked their coaching calls. Some participants suggested reminders about upcoming coaching calls would be beneficial, to ensure they remember and attended.
The current study sought to assess the feasibility of delivering Reboot via online, remote delivery to CCNs, and to provide a preliminary assessment of whether Reboot could potentially increase resilience and confidence in coping with adverse events and decrease burnout, depression, and intention to leave. The results suggested that it is feasible to deliver Reboot via online, remote delivery to CCNs, and found significant increases in resilience and confidence in coping with adverse events and decreases in burnout and depression. Retrospective recall also indicated that nurses believed they had reduced intention to leave after participating in the programme. The qualitative findings echoed the quantitative findings, with CCNs particularly valuing the practical exercises that could be translated into everyday practice.
These findings support those of previous studies indicating that Reboot may be a valuable intervention for HCPs [ 37 , 38 , 44 ], but also extend this in four main ways.
First, the current results were the first to indicate that Reboot may have value in a post-pandemic context. Pre-pandemic, there were already around a third of doctors and nurses suffering from burnout and significant increases reported for work-related stress among healthcare staff [ 37 , 45 ]. However, rates have increased internationally following the onset of the pandemic [ 46 , 47 ]. In the UK, the General Medical Council (GMC) has been running its annual workforce burnout survey since 2018, making it the largest and most comprehensive annual workforce survey in the UK. In 2022, the burnout risk for doctors was at its highest since 2018. In 2021, 46,793 UK medical trainees completed the survey; 43% said that they found their work emotionally exhausting to a high or very high degree, and 33% indicated that they were feeling burnt out from work to either a high or very high degree [ 48 ]. A year later, in 2022, the numbers worsened as 39% (a 6% increase) of trainees indicated that they were feeling burnt out to either a high or very high degree, and 51% of trainees (8% increase) indicated that they found their work emotionally exhausting to a high or very high degree [ 49 ]. While, unfortunately, there is no equivalent study of this scale and magnitude for nurses, this survey, alongside reports from the Nursing and Midwifery Council, show just how extreme the situation has become in healthcare in the UK [ 50 ], and that HCPs desperately need support. While it was possible that these increases in burnout across healthcare professions may have rendered Reboot unworkable or irrelevant, this study shows that Reboot is still feasible and potentially effective, even in the context of psychological changes within the healthcare workforce.
Second, the current results extend the existing literature by showing that Reboot is feasible and potentially effective for CCNs in particular. To date, there are no systematic reviews or meta-analyses that assess the efficacy of intervention to increase resilience or decrease burnout in CCNs. There are, however, reviews that either assess the efficacy of interventions on reducing burnout, or increasing resilience, in physicians and nurses concomitantly [ 35 , 51 , 52 ], or the efficacy of resilience or interventions more generally [ 36 , 53 ]. Overall, these reviews conclude that online programmes and internet-based interventions, as well as psychosocial training interventions, are among the interventions that have a positive effect on burnout and resilience, and that CBT-based resilience interventions and mixed-methods most effective at increasing resilience [ 36 , 51 , 53 ]. However, one major criticism of existing interventions is that they are generic and lack relevance for the work stresses different types of HCPs, or even nurses, are facing. Reboot overcomes this by the fact that it can be tailored to each disciplinary group, including critical care nurses or other specialist areas of nursing, ensuring relevance and saliency of the material for specific discipline groups, rather than for HCPs more generally. For example, CCNs will require different content to be included in a resilience and burnout intervention that is salient and acceptable to them, compared to trainee doctors, surgeons or midwives [ 37 ] but also compared to other nurses. CCNs tend to have different psychological profiles, compared to non-CCNs. For example, nurses working on either orthopaedic or dialysis wards have been found to have much lower burnout scores, compared to nurses working on critical care units [ 54 ] – a difference that has likely been further exacerbated by the pandemic, and effective resilience interventions must take this into account. This will also be a challenge for implementation into practice, as delivery of Reboot would need to be planned and tailored in advance for each HCP group.
Third, the current results also add to the wealth of evidence for the efficacy of person-directed interventions [ 36 , 51 ]. Person-directed interventions can be defined as those which aim to improve an individual’s capacity to cope with the demands of their job, which is often achieved via mindfulness or CBT programmes. While the quantitative findings highlight that Reboot is feasible and potentially effective for CCNs, the qualitative findings add important knowledge to the aspects of person-directed interventions which CCNs found valuable. For example, participants especially valued the practical applications of the programme which helped them, and by proxy, their peers, cope with the demands of their critical care nursing. In this context, it is not possible to suggest that Reboot can be considered superior to other existing interventions for nurses but as one of several candidate interventions which should be tested using more rigorous research designs. However, it should be noted that Reboot has some unique features not shared with other existing interventions: for example, it involves a mixed-modality format, ensuring the benefit of both peer support and one-to-one confidential space with a therapist.
It is clear that interventions, such as Reboot, cannot compensate for organisational failings; and should be used alongside, rather than in place of, organisational interventions [ 19 , 37 , 55 ]. However, organisational changes are often decided at a regional or national level and influenced by political and economic factors. As such they can be challenging to implement. In this context, person-directed interventions are often appealing to organisations as they are within their decision-making latitude/capability to select and deliver. At the same time though, staff often do not currently have the time to attend, and engage with, wellbeing programmes on offer, leading to lack of uptake and furthering intention to leave among NHS employees [ 56 ]. Thus, organisational changes that allow the attendance of, and engagement with, wellbeing programs are desperately needed, alongside changes that have been associated with reduced burnout in nursing, such as higher pay, more work flexibility, higher autonomy and fewer/better working hours [ 57 , 58 , 59 , 60 ].
Fourth, the present study also contributes to a growing literature which is focused on the prevention rather than amelioration of work-related mental distress. Research is starting to highlight the importance of higher levels of resilience as protective factors against burnout and the development of post-traumatic-stress disorder (PTSD) for CCNs, and beyond [ 30 , 36 , 61 , 62 , 63 ]. For example, a 2021 study conducted in Poland [ 63 ] found that higher levels of resilience were associated with lower levels of burnout and secondary traumatic stress, while exposure to secondary traumatic stress was positively related to burnout. This supports the development, and implementation, of prophylactic resilience interventions for healthcare staff, rather than ameliorative burnout or PTSD interventions.
Limitations
While strengths of the current study include its mixed-methods design, which can elucidate not just the potential impact of the intervention but also the mechanisms underlying this, there are a number of limitations.
Firstly, the current uncontrolled study design means that causal associations between Reboot and the outcomes measured cannot be assumed. Higher quality evidence, perhaps in the form of a wait-list control design or randomised controlled trial, is now needed.
Secondly, intention to leave scores were collected retrospectively for pre- and post-Reboot, thus future work should include intention to leave measures from baseline.
Thirdly, the majority of workshop and coaching sessions were delivered by the same therapist, a future trial should ensure the inclusion of multiple therapists. The therapist also encouraged the completion of outcome measures (especially at Time 2, post completion of second workshop), which means the therapist was not entirely independent of the evaluation.
Fourth, non-completers were not further followed up or invited to interview. Future research should consider their perspectives too.
Fifth, due to the study focus on CCNs, generalization to nurses working outside of critical care is not possible.
The current results suggest that it is feasible to deliver Reboot via online delivery to CCNs, and that it is associated with self-reported increases in resilience and confidence in coping with adverse events and decreases in burnout and depression. Participants also reported that their intention to leave reduced following the programme. The qualitative findings echoed the quantitative findings, with CCNs particularly valuing the practical exercises that could be translated into everyday practice. These findings, alongside those of the previously investigated in-person (rather than remote) version support the evidence-base and efficacy of Reboot. However, a randomised controlled trial design is now needed to more fully and robustly ascertain the efficacy of Reboot.
Availability of data and materials
Anonymised behavioural data and statistical analysis may be requested via email from Dr. KS Vogt, after data collection and publication of results.
Abbreviations
Brief Resilience Scale
Cognitive Behavioural Therapy
Critical Care Nurse(s)
Healthcare professional(s)
UK National Health Service
Patient Health Questionnaire
Post-traumatic stress disorder
Recovery boosting coaching programme
Senior Research Fellow
United Kingdom
World Health Organization. Patient safety: fact sheet. World Health Organization; 2019. Internet, Cited 2023 May 10. Available from: https://www.who.int/news-room/fact-sheets/detail/patient-safety
Google Scholar
Elliott RA, Camacho E, Jankovic D, Sculpher MJ, Faria R. Economic analysis of the prevalence and clinical and economic burden of medication error in England. BMJ Qual Saf. 2021;30(2):96–105.
Article PubMed Google Scholar
Nibbelink C, Brewer B. Decision-making in nursing practice: an integrative literature review Christine. J Clin Nurs. 2018;27(5–6):917–28.
Article PubMed PubMed Central Google Scholar
Ma RH, Zhao XP, Ni ZH, Xue XL. Paediatric oncology ward nurses’ experiences of patients’ deaths in China: a qualitative study. BMC Nurs. 2021;20(1):1–8.
Article Google Scholar
Page P, Simpson A, Reynolds L. Bearing witness and being bounded: the experiences of nurses in adult critical care in relation to the survivorship needs of patients and families. J Clin Nurs. 2019;28(17–18):3210–21.
Wu A, Shapiro J, Harrison R, Scott S, Conners C, Kenney L, et al. The impact of adverse events on clinicians: What’s in a name? J Patient Saf. 2020;16(1):65–72.
Article CAS PubMed Google Scholar
Bohlken J, Schömig F, Lemke MR, Pumberger M, Riedel-Heller SG. COVID-19-Pandemie: Belastungen des medizinischen Personals. Psychiatr Prax. 2020;47(04):190–7.
Britt TW, Shuffler ML, Pegram RL, Xoxakos P, Rosopa PJ, Hirsh E, et al. Job demands and resources among healthcare professionals during virus pandemics: a review and examination of fluctuations in mental health strain during COVID-19. Appl Psychol. 2021;70(1):120–49.
Mehta S, Machado F, Kwizera A, Papazian L, Moss M, Azoulay É, et al. COVID-19: a heavy toll on health-care workers. Lancet Respir Med. 2021;9(3):226–8.
Article CAS PubMed PubMed Central Google Scholar
Browne D, Roy S, Phillips M, Shamon S, Stephenson M. Supporting patient and clinician mental health during COVID-19. Can Fam Physician. 2020;66(7):E190–2.
PubMed PubMed Central Google Scholar
Montgomery CM, Humphreys S, McCulloch C, Docherty AB, Sturdy S, Pattison N. Critical care work during COVID-19: a qualitative study of staff experiences in the UK. BMJ Open. 2021;11(5). https://bmjopen.bmj.com/content/11/5/e048124.long .
Seah KM. Redeployment in COVID-19: old dogs and new tricks. Emerg Med J. 2020;37(7):456.
Sindhu KK. Schrödinger’s resident: redeployment in the age of COVID-19. Acad Med. 2020;95(9):1353.
Mosheva M, Gross R, Hertz-Palmor N, Hasson-Ohayon I, Kaplan R, Cleper R, et al. The association between witnessing patient death and mental health outcomes in frontline COVID-19 healthcare workers. Depress Anxiety. 2021;38(4):468–79.
Shah SHA, Haider A, Jindong J, Mumtaz A, Rafiq N. The impact of job stress and state anger on turnover intention among nurses during COVID-19: the mediating role of emotional exhaustion. Front Psychol. 2022;12:810378.
Harris ML, McLeod A, Titler MG. Health experiences of nurses during the COVID-19 pandemic: a mixed methods study. West J Nurs Res. 2023;45(5):443–54.
Alharbi J, Jackson D, Usher K. The potential for COVID-19 to contribute to compassion fatigue in critical care nurses. J Clin Nurs. 2020;29(15–16):2762–4.
Dennis JM, McGovern AP, Vollmer SJ, Mateen BA. Improving Survival of Critical Care Patients with Coronavirus Disease 2019 in England: A National Cohort Study, March to June 2020. Crit Care Med. 2021;49:209–14.
Vogt KS, Grange A, Johnson J, Marran J, Budworth L, Coleman R, et al. Study protocol for the online adaptation and evaluation of the ‘reboot’ (recovery-boosting) coaching programme, to prepare critical care nurses for, and aid recovery after, stressful clinical events. Pilot Feasibility Stud. 2022;8(1):1–10.
Vogt KS, Simms-Ellis R, Grange A, Griffiths ME, Coleman R, Harrison R, et al. Critical care nursing workforce in crisis: a discussion paper examining contributing factors, the impact of the COVID-19 pandemic and potential solutions. J Clin Nurs. 2023;32:7125–34.
Moll V, Meissen H, Pappas S, Xu K, Rimawi R, Buchman TG, et al. The coronavirus disease 2019 pandemic impacts burnout syndrome differently among multiprofessional critical care clinicians - a longitudinal survey study. Crit Care Med. 2022;50(3):440–8.
Greenberg N, Weston D, Hall C, Caulfield T, Williamson V, Fong K. Mental health of staff working in intensive care during Covid-19. Occup Med. 2021;71(2):62–7.
Article CAS Google Scholar
Said RM, El-Shafei DA. Occupational stress, job satisfaction, and intent to leave: nurses working on front lines during COVID-19 pandemic in Zagazig City, Egypt. Environ Sci Pollut Res. 2021;28(7):8791–801.
Pan L, Xu Q, Kuang X, Zhang X, Fang F, Gui L, et al. Prevalence and factors associated with post-traumatic stress disorder in healthcare workers exposed to COVID-19 in Wuhan, China: a cross-sectional survey. BMC Psychiatry. 2021;21(1):1–9.
Crowe S, Howard AF, Vanderspank-wright B, Gillis P, Mcleod F. The effect of COVID-19 pandemic on the mental health of Canadian critical care nurses providing patient care during the early phase pandemic: A mixed method study Sarah. Intensive Crit Care Nurs. 2021;63:102999.
Heesakkers H, Zegers M, van Mol MM, van den Boogaard M. The impact of the first COVID-19 surge on the mental well-being of ICU nurses: a nationwide survey study. Intensive Crit Care Nurs. 2021;65:103034.
Cortese CG. Predictors of critical care nurses’ intention to leave the unit, the hospital, and the nursing profession. Open J Nurs. 2012;02(03):311–26.
Labrague LJ, de Los Santos JA. Fear of COVID-19, psychological distress, work satisfaction and turnover intention among frontline nurses. J Nurs Manag. 2021;29(3):395–403.
Tolksdorf K, Tischler U, Heinrichs K. Correlates of turnover intention among nursing staff in the COVID-19 pandemic: a systematic review. BMC Nurs. 2022;21(1):174.
Montgomery A, Panagopoulou E, Esmail A, Richards T, Maslach C. Burnout in healthcare: the case for organisational change. BMJ. 2019;366:12777.
Mealer BM, Jones J, Meek P. Factors affecting Resilience and development of posttraumatic stress disorder in critical care nurses. Am J Crit Care Nurs. 2017;26(3):184–92.
Rushton CH, Batcheller J, Schroeder K, Donohue P. Burnout and Resilience among nurses practicing in high- intensity settings. Am J Crit Care Nurs. 2015;24(5):412–20.
Johnson J, Panagioti M, Bass J, Ramsey L, Harrison R. Resilience to emotional distress in response to failure, error or mistakes: a systematic review. Clin Psychol Rev. 2017;52:19–42.
Resilience JJ. The bi-dimensional framework. In: Wood A, Johnson J, editors. The Wiley handbook of positive clinical psychology. Wiley-Blackwell; 2016.
Kunzler AM, Helmreich I, Chmitorz A, König J, Binder H, Wessa M, et al. Psychological interventions to foster resilience in healthcare professionals. Cochrane Database Syst Rev. 2020;7(7). https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8121081/ .
Joyce S, Shand F, Tighe J, Laurent SJ, Bryant RA, Harvey SB. Road to resilience: a systematic review and meta-analysis of resilience training programmes and interventions. BMJ Open. 2018;8(6):1–9.
Johnson J, Simms-Ellis R, Janes G, Mills T, Budworth L, Atkinson L, et al. Can we prepare healthcare professionals and students for involvement in stressful healthcare events? A mixed-methods evaluation of a resilience training intervention. BMC Health Serv Res. 2020;20(1):1–14.
Al-Ghunaim T, Johnson J, Biyani CS, Coleman R, Simms-Ellis R, O’Connor DB. Evaluation of the reboot coaching workshops among urology trainees: a mixed method approach. BJUI Compass. 2023;4(5):533–42.
Kirkpatrick DL. Evaluating training programs: the four levels. Emeryville: Berrett-Koehler Publishers; 1994.
Smith BW, Dalen J, Wiggins K, Tooley E, Christopher P, Bernard J. The brief resilience scale: assessing the ability to bounce back. Int J Behav Med. 2008;15(3):194–200.
Demerouti E, Bakker AB. The Oldenburg burnout inventory: a good alternative to measure burnout (and engagement). 2007. Internet, Available from: https://www.isonderhouden.nl/doc/pdf/arnoldbakker/articles/articles_arnold_bakker_173.pdf
Kroenke K, Spitzer RL, Williams JBW. The PHQ-9: validity of a brief depression severity measure. J Gen Intern Med. 2001;16(9):606–13.
Braun V, Clarke V. Using thematic analysis in psychology. Qual Res Psychol. 2006;3(2):77–101.
Johnson J, Pointon L, Talbot R, Coleman R, Budworth L, Simms-Ellis R, Johnson, J., Pointon, L., Talbot, R., Coleman, R., Budworth, L., Simms-Ellis, R., Vogt, K., Tsimpida, D., Biyani, C. S., Harrison, R., Cheung, G., Melville, C., Jayagopal, V. & Lea, W. (2023). Reboot coaching programme: a mixed-methods evaluation assessing resilience, confidence, burnout and depression in medical students. Scott Med J, in press.
Hall LH, Johnson J, Watt I, Tsipa A, O’Connor DB. Healthcare staff wellbeing, burnout, and patient safety: a systematic review. PLoS One. 2016;11(7):1–12.
Wise J. Covid-19: experts divide into two camps of action-shielding versus blanket policies. BMJ. 2020;370:m3702.
Wei H, Aucoin J, Kuntapay GR, Justice A, Jones A, Zhang C, et al. The prevalence of nurse burnout and its association with telomere length pre and during the COVID-19 pandemic. PLoS One. 2022;17(3 March):1–14.
General Medical Council. National training survey 2021 - results. 2021. Internet, Available from: https://www.gmc-uk.org/-/media/documents/national-training-survey-results-2021%2D%2D-summary-report_pdf-87050829.pdf
General Medical Council. National training survey 2022 results. 2022. Internet, Available from: https://www.gmc-uk.org/-/media/documents/national-training-survey-summary-report-2022-final_pdf-91826501.pdf
Nursing & Midwifery Council. Nursing and midwifery register grows but so does number of people leaving. 2022, Cited 2023 Nov 15]. Internet, Available from: https://www.nmc.org.uk/news/news-and-updates/nursing-and-midwifery-register-grows-but-so-does-number-of-people-leaving/
Aryankhesal A, Mohammadibakhsh R, Hamidi Y, Alidoost S, Behzadifar M, Sohrabi R, et al. Interventions on reducing burnout in physician and nurses: a systematic review. Med J Islam Repub Iran. 2019;33:77.
Zhang YY, Han WL, Qin W, Yin HX, Zhang CF, Kong C, et al. Extent of compassion satisfaction, compassion fatigue and burnout in nursing: a meta-analysis. J Nurs Manag. 2018;26(7):810–9.
Awa WL, Plaumann M, Walter U. Burnout prevention: a review of intervention programs. Patient Educ Couns. 2010;78(2):184–90.
Ahmadi Q, Azizkhani R, Basravi M. Correlation between workplace and occupational burnout syndrome in nurses. Adv Biomed Res. 2014;3(44). https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3949345/ .
Public Health England. Interventions to prevent burnout in high risk individuals: evidence review. 2016. Available from: https://assets.publishing.service.gov.uk/media/5a81a3aee5274a2e8ab55122/25022016_Burnout_Rapid_Review_2015709.pdf .
Body NPR. NHS pay review Body thirty-fifth report 2022. Office of Manpower Economics; 2022. Internet, Available from: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/1092270/NHSPRB_2022_Accessible.pdf
Alzailai N, Barriball L, Xyrichis A. Burnout and job satisfaction among critical care nurses in Saudi Arabia and their contributing factors: a scoping review. Nurs Open. 2021;8(5):2331–44.
Cañadas-De la Fuente GA, Vargas C, San Luis C, García I, Cañadas GR, Emilia I. Risk factors and prevalence of burnout syndrome in the nursing profession. Int J Nurs Stud. 2015;52(1):240–9.
Moustaka Ε. Sources and effects of work-related stress in nursing. Health Sci J. 2011;4:210–6.
Shah MK, Gandrakota N, Cimiotti JP, Ghose N, Moore M, Ali MK. Prevalence of and factors associated with nurse burnout in the US. JAMA Netw Open. 2021;4(2):1–11.
Cacciatori I, Grossi C, D’Auria C, Bruneri A, Casella C. Resilience skills as a protective factor against burnout for health professionals: a cross-sectional study on new hires from the hospital of Lodi. G Ital Med Lav Ergon. 2021;43(2):131–6.
PubMed Google Scholar
Vagni M, Maiorano T, Giostra V, Pajardi D. Protective factors against emergency stress and burnout in healthcare and emergency workers during second wave of COVID-19. Soc Sci. 2021;10(5):178.
Ogi’nska-Bulik N, Michalska P. Psychological Resilience and secondary traumatic stress in nurses working with terminally ill patients—the mediating role of job burnout. Psychol Serv. 2021;18(3):398–405.
Download references
Acknowledgements
The authors would like to thank the following individuals for their contributions to this study: Sobia Bibi and Lucy Chapman, our Industrial placement students Ryan Carter and Rameen Haq, our Steering Group and the CC3N Network, for their support of the study.
This work is funded by the Burdett Trust for Nursing [Grant code SB/ZA/101010662/632762, Funding Stream: Covid-19: Supporting Resilience in the Nursing Workforce] and supported by the NIHR Yorkshire and Humber Patient Safety Translational Research Centre [under grant PSTRC-2016-006]. The sponsor is Bradford Teaching Hospitals [contact details for sponsor: [email protected] ]. Neither study sponsor nor funder have no role in the study design, the collection of data, the management of data, the analysis thereof, or its interpretation.
This report is independent research supported by National Institute for Health and Care Research Yorkshire and Humber ARC [under grant NIHR200166]. The views expressed in this publication are those of the authors and not necessarily those of the National Institute for Health Research or the Department of Health and Social Care.
Author information
Authors and affiliations.
Bradford Institute for Health Research, Bradford Royal Infirmary, Temple Bank House, Duckworth Lane, Bradford, BD9 6RJ, UK
K. S. Vogt, J. Johnson, R. Coleman, R. Simms-Ellis, J. Marran, L. Budworth, R. Lawton & A. Grange
Department of Psychology, University of Leeds, Leeds, LS2 9JT, UK
K. S. Vogt, J. Johnson, R. Simms-Ellis & R. Lawton
School of Population Health, University of New South Wales, Sydney, 2052, Australia
J. Johnson & R. Harrison
Centre for Health Systems and Safety Research: Australian Institute of Health Innovation, Macquarie University, Sydney, Australia
R. Harrison
Leeds Teaching Hospitals NHS Trust, Great George Street, Leeds, LS1 3EX, UK
N. Shearman
Leeds Institute of Rheumatic and Musculoskeletal Medicine, University of Leeds, Leeds, UK
L. Budworth
School of Health and Wellbeing: College of Medical, Veterinary and Life Sciences, University of Glasgow, Clarice Pears Building, Glasgow, G12 8TB, UK
Department of Primary Care & Mental Health, Institute of Population Health, University of Liverpool, Eleanor Rathbone Building, Liverpool, L69 7ZA, UK
West Yorkshire Adult Critical Care Network, Leeds Teaching Hospitals, Leeds, UK
C. Horsfield
NIHR Yorkshire & Humber Patient Safety Research Collaboration, Bradford Teaching Hospitals Foundation Trust, Bradford, UK
Mid Yorkshire Teaching NHS Trust, Wakefield, UK
You can also search for this author in PubMed Google Scholar
Contributions
This work is based on previous work conducted by JJ and RSE. For this project, RSE, JJ, JM, RL, AG, RL, HR and LB conceived the study and initiated the adaptation. NS and CH contributed to the design of the study. Adaptation to online, remote delivery was led by JJ and RSE. The Principal Investigator [and grant holder] is AG. JJ, RSE, AG and KSV worked on the ethical approvals. JJ and RC delivered the workshops, RC delivered the coaching calls. JJ provided regular supervision to RC. KSV led on recruitment, supported by CH, and conducted all data collection [quantitative via online questionnaire and qualitative interviews]. LB and KSV conducted statistical analyses; KSV the qualitative analysis. JJ, AG, RSE and JM assisted with data analysis, when needed. KSV wrote the first version of this paper, all authors have had opportunity to read and contribute to the manuscript prior to submission.
Corresponding author
Correspondence to K. S. Vogt .
Ethics declarations
Ethics approval and consent to participate.
Ethics approval was granted by the University of Leeds Ethics committee for this study. Participants gave full informed consent before participation. The study adheres to both the British Psychological Society’s Code of Ethics and Conduct, as well as Declaration of Helsinki.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Vogt, K.S., Johnson, J., Coleman, R. et al. Can the Reboot coaching programme support critical care nurses in coping with stressful clinical events? A mixed-methods evaluation assessing resilience, burnout, depression and turnover intentions. BMC Health Serv Res 24 , 343 (2024). https://doi.org/10.1186/s12913-023-10468-w
Download citation
Received : 05 April 2023
Accepted : 12 December 2023
Published : 15 March 2024
DOI : https://doi.org/10.1186/s12913-023-10468-w
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Critical care
- Healthcare staff
BMC Health Services Research
ISSN: 1472-6963
- General enquiries: [email protected]
This paper is in the following e-collection/theme issue:
Published on 15.3.2024 in Vol 26 (2024)
Methods and Annotated Data Sets Used to Predict the Gender and Age of Twitter Users: Scoping Review
Authors of this article:
- Karen O'Connor 1 , MSc ;
- Su Golder 2 , PhD ;
- Davy Weissenbacher 3 , PhD ;
- Ari Z Klein 1 , PhD ;
- Arjun Magge 1 , PhD ;
- Graciela Gonzalez-Hernandez 3 , PhD
1 Department of Biostatistics, Epidemiology and Informatics, Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA, United States
2 Department of Health Sciences, University of York, York, United Kingdom
3 Department of Computational Biomedicine, Cedars-Sinai Medical Center, Los Angeles, CA, United States
Corresponding Author:
Karen O'Connor, MSc
Department of Biostatistics, Epidemiology and Informatics
Perelman School of Medicine
University of Pennsylvania
423 Guardian Dr
Philadelphia, PA, 19004
United States
Phone: 1 215 573 8089
Email: [email protected]
Background: Patient health data collected from a variety of nontraditional resources, commonly referred to as real-world data , can be a key information source for health and social science research. Social media platforms, such as Twitter (Twitter, Inc), offer vast amounts of real-world data. An important aspect of incorporating social media data in scientific research is identifying the demographic characteristics of the users who posted those data. Age and gender are considered key demographics for assessing the representativeness of the sample and enable researchers to study subgroups and disparities effectively. However, deciphering the age and gender of social media users poses challenges.
Objective: This scoping review aims to summarize the existing literature on the prediction of the age and gender of Twitter users and provide an overview of the methods used.
Methods: We searched 15 electronic databases and carried out reference checking to identify relevant studies that met our inclusion criteria: studies that predicted the age or gender of Twitter users using computational methods. The screening process was performed independently by 2 researchers to ensure the accuracy and reliability of the included studies.
Results: Of the initial 684 studies retrieved, 74 (10.8%) studies met our inclusion criteria. Among these 74 studies, 42 (57%) focused on predicting gender, 8 (11%) focused on predicting age, and 24 (32%) predicted a combination of both age and gender. Gender prediction was predominantly approached as a binary classification task, with the reported performance of the methods ranging from 0.58 to 0.96 F 1 -score or 0.51 to 0.97 accuracy. Age prediction approaches varied in terms of classification groups, with a higher range of reported performance, ranging from 0.31 to 0.94 F 1 -score or 0.43 to 0.86 accuracy. The heterogeneous nature of the studies and the reporting of dissimilar performance metrics made it challenging to quantitatively synthesize results and draw definitive conclusions.
Conclusions: Our review found that although automated methods for predicting the age and gender of Twitter users have evolved to incorporate techniques such as deep neural networks, a significant proportion of the attempts rely on traditional machine learning methods, suggesting that there is potential to improve the performance of these tasks by using more advanced methods. Gender prediction has generally achieved a higher reported performance than age prediction. However, the lack of standardized reporting of performance metrics or standard annotated corpora to evaluate the methods used hinders any meaningful comparison of the approaches. Potential biases stemming from the collection and labeling of data used in the studies was identified as a problem, emphasizing the need for careful consideration and mitigation of biases in future studies. This scoping review provides valuable insights into the methods used for predicting the age and gender of Twitter users, along with the challenges and considerations associated with these methods.
Introduction
Real-world data are data regarding patients’ health collected outside randomized controlled trials from a variety of nontraditional resources such as electronic health records, medical claims data, or data generated by patients themselves such as social media data that may be used to support study design to develop real-world evidence [ 1 ]. Real-world data from social media have been increasingly recognized as a valuable resource for gaining knowledge about and insight into a variety of health-related research topics, including disease surveillance [ 2 , 3 ], pharmacovigilance [ 4 , 5 ], and mental health [ 6 , 7 ]. They can also be used for the identification of cohorts for potential recruitment into traditional studies [ 8 , 9 ]. In short, social media can readily provide abundant personal health information in real time.
The use of data from social media platforms, particularly Twitter (Twitter, Inc), for health-related research is subject to some inherent limitations in that demographic information (with the exception of location, which is available when the user has enabled the location feature) is not explicitly available through the application programming interface (API) [ 10 ]. Demographic traits, including age, gender, race or ethnicity, location, education, and income, hold significant value in health research. Few studies based on Twitter data incorporated an assessment of Twitter user demographics into their analysis [ 11 ]. Understanding the demographic traits of Twitter users provides significant value when using the data in health research. It not only facilitates sample representativeness, which is crucial for generalizing research findings and ensuring that the conclusions drawn from Twitter data can be extrapolated to broader populations [ 12 ], but also enables subgroup analysis. It allows for the comparison of health-related behaviors, attitudes, and outcomes across different groups and enables targeted interventions and tailored health care strategies [ 13 , 14 ]. Moreover, demographic information is actionable and can assist in designing public health interventions and policies for specific populations based on their needs and concerns as expressed on social media.
Predicting demographic traits is complex and challenging. A user’s profile does not necessarily include such information, and researchers have used other features available in the data, such as names, content of the tweets, or the individual’s network to make predictions. A 2018 systematic review assessed the use of social media to predict demographic traits, finding successful implementation for 14 traits, including gender and age [ 15 , 16 ]. Although the review provided a broad overview of the state of demographic prediction using social media, the details of the machine learning (ML) methods used were not reviewed. A recent review provided insights into the methods used for predicting the race and ethnicity of Twitter users [ 17 ].
In this study, our objective was to present a scoping review of automated methods used for predicting the age and gender of Twitter users to provide an overview of the techniques published since 2017. We focused our review on studies that used Twitter, as it is the most commonly used social media platform for this research [ 15 ]. Twitter is an attractive platform to use in research, as the terms of use for this platform are well understood by both users and researchers, it includes an API, and the data on it are abundant for health-related research [ 18 ].
Although other demographic traits such as location, education, and income can provide valuable insights, the age and gender of Twitter users present distinct advantages and considerations for health research. Given the differences in disease presentation by gender, such as with acute coronary syndrome [ 19 ], and by age, such as with COVID-19 [ 20 ], identifying the age and gender of the users included in studies using Twitter data may elicit insights into disease prevalence, patterns, and variations across different subgroups in disease presentation or treatment response [ 21 , 22 ]. Age and gender also play crucial roles in shaping health behaviors and attitudes. For example, studying age and gender differences in smoking habits [ 23 ], physical activity levels [ 24 ], and adherence to medical treatments [ 25 , 26 ] can provide insights into effective interventions and health promotion campaigns for specific groups. Although Twitter users are generally representative of the population, there is a certain degree of skew in their demographics: there is an overrepresentation of individuals aged <30 years, whereas individuals aged >65 years are underrepresented when compared with the overall demographics of the US population [ 27 , 28 ]. Therefore, it is important to include the age and gender of Twitter users in a study to enable the accurate reporting of findings, making them specific to certain subgroups, or to make any necessary adjustments to account for potential biases that may arise from these demographic differences.
Although studies aimed at predicting Twitter users’ gender began as early as 2011 [ 29 - 33 ] and efforts aimed at detecting the age of Twitter users have been made since 2013 [ 34 - 36 ], it is only since 2017 that the language processing community shifted its methods away from handcrafted rules and represented text documents with dense vectors to train deep neural networks (DNNs) [ 37 , 38 ], resulting in a noticeable increase in performance for many applications. We sought to examine whether these increases in performance were evident in the methods used for the prediction of the age and gender of Twitter users.
We report this review following the PRISMA-ScR (Preferred Reporting Items for Systematic Reviews and Meta-Analyses Extension for Scoping Reviews) [ 39 ] methodology. The completed PRISMA-ScR checklist is available in Table S1 in Multimedia Appendix 1 . We searched several databases to identify studies on the prediction of Twitter users’ age or gender or both. Our database search strategy combines 3 facets: facet 1 includes terms related to Twitter, facet 2 consists of terms for age or gender, and facet 3 consists of terms for methods of prediction such as ML. The search strategy was translated as appropriate for each database. The detailed search strategy is available in Multimedia Appendix 2 . The ML term facet was expanded using terms from related reviews by Hinds and Joinson [ 15 ] and Umar et al [ 40 ]. The search criteria were limited to peer-reviewed journals, conference proceedings, books, and theses.
The following databases were searched with a publication date range of 2017 or later ( Textbox 1 ).
- ACL (Association for Computational Linguistics) Anthology: 5080, of which the first 50 records were screened
- ACM (Association for Computing Machinery) Digital Library: 23
- Cumulative Index to Nursing & Allied Health (CINAHL): 57
- Embase: 262
- Google Scholar: 767,000, of which the first 50 records were screened
- IEEE (Institute of Electrical and Electronics Engineers) Xplore: 23
- Library and Information Science Abstracts: 31
- Library, Information Science and Technology Abstracts: 48
- Proquest Dissertations and Theses—United Kingdom and Ireland: 58
- Ovid MEDLINE: 183
- PsycINFO: 104
- Science Citation Index, Social Science Citation Index, Conference Proceedings Citation Index—Science, and Conference Proceedings Citation Index—Social Science and Humanities: 131
Citations were exported to a shared EndNote (Clarivate) library for deduplication. Using the Population, Intervention, Comparison, Outcomes, and Study Design (PICOS) [ 41 ] framework, we developed a list of inclusion and exclusion criteria (refer to the Inclusion and Exclusion Criteria section), and 2 screeners from the research team screened the results independently, with disputes discussed after screening and a consensus decision reached. In addition, given that search engines and unmanageable data sources are recommended to be included as secondary data sources [ 42 - 44 ], the first 50 records from both ACL (Association for Computational Linguistics) Anthology and Google Scholar were screened using the aforementioned methods. We set a limit on the number of results screened, as the relevance of the results is ranked by the search engines, with the most relevant results listed first [ 45 - 48 ].
Inclusion and Exclusion Criteria
We framed our research question using the PICOS framework. Table 1 outlines our specific inclusion and exclusion criteria. As explained in the Introduction section, we restricted the date of our search to include only publications from 2017 and beyond. No language restrictions were applied to the inclusion criteria; however, financial and logistical restraints allowed us to include only studies written in English, Spanish, Chinese, or French.
a N/A: not applicable.
Data Extraction
From each included paper, we extracted the following data: the year of publication, publication type (journal, conference paper, book chapter, or thesis), demographic predicted (gender, age, or both), language of tweets, size of the data set, collection method for the data set, details of prediction models, features used in the models (posts, profile, and images), performance of the models, name of any software used for prediction, measures used to assess the methods and results of any evaluation, and the availability of data or code. The included papers were distributed among the authors for data extraction. The extracted data were validated by another author (KO).
Our database searches resulted in 981 studies, which were retrieved and entered into an EndNote library, where duplicates were removed, leaving 684 (69.7%) studies for sifting.
After the abstract review, 172 (25.1%) of 684 studies were deemed potentially relevant by either one of the independent sifters (SG and KO). The full texts of these studies were screened independently, and disagreements were discussed, resulting in the inclusion of 74 (43%) studies [ 49 - 122 ] and exclusion of 98 (57%) studies ( Figure 1 ).

Characteristics of the Included Studies
Among the 74 included studies ( Multimedia Appendices 3 [ 49 - 52 , 54 - 63 , 65 , 67 - 72 , 74 - 89 , 91 - 93 , 96 - 99 , 101 - 122 ] and 4 [ 51 , 53 , 55 , 56 , 59 , 60 , 63 - 67 , 70 , 73 , 74 , 77 , 80 , 83 , 84 , 87 , 90 , 94 , 95 , 99 - 101 , 108 , 110 , 112 , 116 , 118 - 120 ]), the majority (n=42, 57%) focused on predicting only the gender of the individual, 24 (32%) explored predicting both gender and age, and 8 (11%) focused solely on predicting age. Most of the studies were published in conference proceedings (44/74, 59%), followed by journal articles (28/74, 38%), theses (2/74, 3%), and a book chapter (1/74, 1%).
In 42 (57%) of the 74 studies, developing methods to predict Twitter users’ age or gender or both was the primary purpose. In the remaining studies (32/74, 43%), the identification of the demographic characteristics of Twitter users was secondary. Within this last group, 9 (28%) studies developed ad-hoc methods to determine age, gender, or both, whereas the others used open-source models (13/32, 41%) or off-the-shelf software (10/32, 31%).
Studies Developing Ad-Hoc Methods for Gender and Age Prediction
Of the 74 studies, 44 (59%) developed ad-hoc methods to predict the Twitter users’ gender. Of these 44 studies, 32 (73%) predicted the users’ gender alone [ 49 , 50 , 52 , 54 , 57 , 58 , 68 , 69 , 71 , 72 , 75 , 76 , 79 , 81 , 82 , 85 , 86 , 89 , 92 , 93 , 96 , 102 , 104 - 107 , 111 , 113 , 115 , 117 , 121 , 122 ], and 12 (27%) predicted gender along with age [ 51 , 55 , 65 , 70 , 80 , 83 , 87 , 101 , 108 , 110 , 112 , 116 ].
Most studies that developed ad-hoc methods (41/44, 93%) approached the problem of gender prediction as a binary classification task, predicting whether the label male or female applies to each user account, whereas 4% (3/44) of studies [ 93 , 112 , 119 ] added the classification of organization or brand.
We found that approaches to predict gender included tweets written in multiple languages, including English [ 52 , 82 , 83 , 92 , 93 , 115 , 117 ], German [ 76 ], Slovenian [ 106 ], Italian [ 49 ], Japanese [ 89 ], Arabic and Egyptian [ 57 , 58 , 79 ], French, Dutch, Portuguese, and Spanish, and a multilingual study assessed tweets written in 28 languages and dialects [ 112 ].
For the training and validation of the ad-hoc approaches for gender detection, some studies (19/44, 43%) used previously created annotated corpora, whereas others (27/44, 61%) collected data directly from Twitter. Among the 19 studies that used previously annotated data sets, 9 (47%) [ 55 , 57 , 58 , 68 , 70 , 86 , 87 , 96 , 121 ] used corpora from the PAN-Conference and Labs of the Evaluation Forum (CLEF; PAN-CLEF) author profiling tasks [ 123 - 129 ], whereas 10 (53%) studies [ 72 , 75 , 83 , 85 , 93 , 104 , 105 , 115 , 117 , 122 ] relied on data sets from other studies [ 113 , 130 - 136 ].
In the 27 (61%) studies that collected data directly from Twitter, different components of Twitter accounts were used. These components were used either for manually or semiautomatically validating the gender of a user or for computing features describing the user to train a classifier ( Multimedia Appendix 5 [ 49 - 122 ]). Despite data limitations from the Twitter API, it was the main source of data collection, with 22 (24%) studies [ 49 - 52 , 54 , 69 , 71 , 76 , 79 , 81 , 89 , 92 , 101 , 102 , 106 - 108 , 110 , 111 , 116 , 117 , 121 ] collecting data either as a random sample from the Twitter Streaming API or based on keywords or geographic location from the Twitter Search API. Of the 5 studies not using the Twitter API, 1 (20%) [ 82 ] collected data using a scraping tool, 3 (60%) [ 80 , 112 , 113 ] used a random sample from a collection of 10% of tweets from 2014 to 2017 or the Twitter archive, and 1 (20%) did not specify its data source [ 65 ].
The 24 studies that created a labeled data set ( Multimedia Appendix 6 [ 49 , 51 - 54 , 63 , 64 , 66 , 69 , 71 , 73 , 76 , 77 , 80 , 82 , 89 , 90 , 92 , 106 - 108 , 110 , 112 , 113 , 116 - 118 , 120 ]) to train and test or to validate the performance of the system determined the gender of the users using multiple components of their Twitter accounts ( Multimedia Appendix 5 ). A total of 11 (46%) studies labeled the data through manual annotation, where the annotators determined the gender using profile pictures [ 52 , 54 ], user names [ 71 ], profiles [ 89 ], or a combination of these [ 76 , 82 , 92 , 106 , 108 , 110 , 116 ]. There were 11 (46%) studies that automatically or semiautomatically labeled their data sets via the detection of self-reports or gender-identifying terms (eg, mother, son, and uncle) [ 69 , 80 , 108 , 110 , 112 , 117 ], the user’s name [ 49 , 107 , 113 ], or declarations on other linked social media [ 116 , 117 ]. A total of 3 (13%) studies created their labeled data sets by using the accounts of famous social media influencers [ 65 ] or using an unspecified collection of users whose gender is known [ 51 , 79 ]. Of the 24 studies, only 8 (33%) reported data availability. Of the 8 studies, 6 (75%) stated availability by request , and 2 (25%) had working links to the whole corpus ( Multimedia Appendix 6 ).
Nonpersonal Accounts
A Twitter account may not be authored by or represent a single person. There are organization or company accounts as well as bot accounts. A bot is an automatic or semiautomatic user account. Some bot accounts identify themselves as such and may be used to automatically amplify news or tweets related to a certain topic. Others may emulate human accounts and be used with a more malicious intent to sow discord, manipulate public opinion, or spread misinformation. There were 9 (12%) of the 74 included studies [ 49 , 76 , 92 , 93 , 96 , 103 , 104 , 106 , 112 ] that removed nonpersonal (organization) accounts when they manually annotated their collections. Some studies (11/74, 15%) implemented heuristics to explicitly detect and remove nonpersonal accounts [ 49 , 50 , 59 , 71 , 81 , 107 , 113 , 122 ], bot accounts [ 98 ], or both [ 79 , 137 ]. Others (39/74, 53%) used previously annotated data sets consisting of only personal accounts, labeled and removed nonpersonal accounts, or collected their data sets based on self-reports of age and gender or other identifiable personal information. The remaining (15/74, 20%) studies provided no details on how or whether these accounts were removed ( Multimedia Appendix 5 ).
Features and Models
The reviewed studies used data labeled with the user’s gender to build and evaluate classification models based on features describing the tweets (such as n-grams, word embeddings, hashtags, and URLs) [ 57 , 58 , 65 , 68 - 71 , 75 , 79 , 82 , 86 , 87 , 92 , 96 , 104 , 109 , 113 , 121 ], features derived from the users’ profile metadata (such as user names, bio, followers, and users followed) [ 49 , 51 , 52 , 72 , 80 , 85 , 112 , 115 , 122 ], features derived from a combination of their profile metadata and tweets [ 52 , 54 , 76 , 83 , 93 , 107 , 108 , 110 , 117 ] or images [ 52 , 80 , 108 , 112 , 116 ]. Of the 74 studies, 1 (3%) study from Japan included the user’s geographic information under the assumption that, culturally, a person of a certain demographic is more likely to frequent specific places [ 89 ].
Among the systems that used handcrafted features (25/44, 57%), most (13/25, 52%) achieved their best results using a support vector machine (SVM) [ 49 , 54 , 65 , 72 , 82 , 85 , 86 , 104 - 106 , 113 , 116 , 138 ], whereas others (12/25, 48%) used logistic regression [ 87 , 107 , 110 ], naive Bayes [ 51 , 92 ], random forests [ 80 ], bag of trees [ 70 ], extreme gradient boosting [ 89 ], or ensemble approaches [ 76 , 79 , 107 , 122 ] (details are provided in Table 2 ). Other systems used deep learning methods (15/44, 34%) such as DNNs, convolutional neural networks, feed forward neural networks or recurrent neural networks [ 55 , 68 , 71 , 75 , 93 , 115 , 121 ], bidirectional long-term short-term memory [ 58 ], gated recurrent units [ 57 ], graph recursive neural networks [ 83 ], and multimodal deep learning networks [ 108 , 112 ].
One of the studies created a meta-classifier ensemble classifying users based on the predictions of multiple individual classifiers [ 117 ], including SVM, bidirectional encoder representations from transformers, and 2 existing models [ 112 , 139 ]. Another study created a DNN for learning with label proportion, a semisupervised approach [ 52 ]. The results of the best-performing deep learning model as reported in each study are presented in Table 3 . Studies that used lexical matching (4/44, 9%) of the user’s name to a curated name dictionary [ 50 , 81 , 101 , 102 ] to determine gender reported no validation or performance metrics.
a SVM: support vector machine.
b DT: decision tree.
c RF: random forest.
d N/A: not applicable.
e LogR: logistic regression.
f NB: naive Bayes.
g PME: projection matrix extraction.
h SVC: support vector classifier.
i PNN: probabilistic neural network.
j XGBoost: extreme gradient boosting.
k LinR: linear regression.
a LLP: learning with label proportions.
b N/A: not applicable.
c LDA: latent Dirichlet allocation.
d CNN: convolutional neural network.
e GRNN: graph recurrent neural network.
f DMT: deep multimodal multitask.
g GRU: gated recurrent network.
h RNN: recurrent neural network.
i BILSTM: bidirectional long-term short-term memory.
j FFNN: feed forward neural network.
k mmDNN: multimodal deep neural network.
l biGRU: bidirectional gated recurrent unit.
m DNN: deep neural network.
n M3: multimodal, multilingual, and multi-attribute system.
o SVM: support vector machine.
Performance
Performance results from the traditional ML methods cannot be directly compared against the deep learning methods used, as they were evaluated against different gold-standard corpora, and they used nonstandardized reporting metrics. However, looking at the overall results in terms of F 1 -score, the results of the studies using deep learning had a relatively narrower range of reported performance (0.84-0.96), with a higher minimum of 0.84 and higher maximum of 0.96, compared with the reported performance range for traditional ML methods, which spans from 0.64 to 0.93.
We found 19 studies that developed ad-hoc methods to predict the Twitter user’s age, among which 7 (37%) predicted age exclusively [ 53 , 64 , 66 , 73 , 90 , 94 , 95 ]. All but 1 (5%) of the studies [ 80 ] approached the detection of Twitter users’ age as an automatic classification of predefined age groups. The number of age groups varied across the studies ( Table 3 ), with the ages categorized into 2 [ 53 , 73 , 83 , 110 , 116 ], 3 [ 51 , 66 , 90 , 94 , 95 , 101 , 108 ], 4 [ 70 , 112 ], or more [ 55 , 64 , 65 , 87 ] groups. The range of ages within the groups also varied across the studies; for example, across the 5 studies that took a binary classification approach, Guimaraes et al [ 73 ] used 13 to 19 years and ≥20 years as the 2 age groups, Volkova et al [ 110 ] and Kim et al [ 83 ] used 18 to 23 years or ≥25 years, Xiang et al [ 116 ] used ≤30 years or >30 years, and Ardehaly and Culotta [ 53 ] used <25 years and ≥25 years.
Except for 2 (11%) studies that did not report the language of the tweets used [ 51 , 73 ], all studies used English language tweets. A total of 8 (42%) studies extended their systems to include additional languages, including Spanish [ 55 , 64 , 87 , 110 ], Dutch [ 87 , 94 , 95 ], Filipino [ 65 ], and multiple languages [ 112 ].
Most studies (9/19, 47%) that developed new algorithms prepared new data sets to evaluate them with data retrieved directly using Twitter’s API [ 51 , 53 , 66 , 73 , 90 , 108 ] or used other sources of data for this purpose [ 64 , 80 , 112 ] ( Multimedia Appendix 4 ). Several studies used data sets made available by other studies to train or evaluate their algorithms: among the 19 studies, 2 (11%) studies [ 94 , 95 ] combined data sets from Sloan et al [ 34 ], Nguyen et al [ 36 ], and Morgan-Lopez et al [ 90 ]; Kim et al [ 83 ] used the data set from Volkova et al [ 140 ]; and 3 (15%) studies [ 55 , 70 , 87 ] used data sets that were created for the PAN-CLEF author profiling shared tasks [ 124 - 126 ]. The studies that prepared new data sets ( Multimedia Appendix 6 ) labeled users’ age groups by automatically or semiautomatically searching (1) for tweets that self-reported birthday announcements or age [ 53 , 80 , 90 , 108 , 110 , 112 ], (2) for tweets in which a user was wished a happy birthday [ 90 ], (3) for profiles that self-reported age [ 64 , 66 , 108 , 112 ], (4) for profiles that mentioned age-related keywords (eg, grandparent ) [ 66 , 112 ], or (5) for manual annotation based on images or profile metadata [ 112 , 116 , 140 ] or (6) by subjectively perceiving age groups based on the content of individual tweets [ 73 ]. In 1 (5%) study [ 51 ], a mixture of self-reported information and demographic information of known individuals was used to label the data. Similar to studies on gender, the reported availability of the corpora was scarce. Only 5 (26%) studies reported that their data sets were available, 2 (40%) by request, 1 (20%) provided a link to the whole data set, and 2 (40%) provided a link to a sample of the corpus ( Multimedia Appendix 6 ).
The studies used labeled age groups to evaluate classification models based on the features of the users’ profile metadata (eg, user names, bio, followers, and users followed) [ 51 , 53 , 64 , 80 , 112 ], a combination of their profile metadata and tweets (eg, n-grams, word embeddings, hashtags, and URLs) [ 73 , 83 , 90 , 94 , 95 , 108 , 110 ], tweet texts only [ 65 , 66 , 70 , 87 ], or images [ 80 , 108 , 112 , 116 ].
For automatic classification, most studies (12/19, 63%) used traditional supervised ML methods, including logistic regression [ 51 , 66 , 87 , 90 , 110 ], Bayesian probabilistic inference [ 64 ], random forests [ 80 ], bag of trees [ 70 ], or SVM [ 65 , 116 ], or a semisupervised approach, learning from label proportion [ 53 ]. Other studies (7/16, 37%) used deep learning methods such as convolutional neural networks [ 55 , 73 , 94 , 95 ], graph recursive neural networks [ 83 ], and multimodal deep learning networks [ 108 , 112 ]. The best-performing systems for each study are listed in Tables 4 and 5 . Of the 19 studies, 1 (5%) [ 101 ] classified age based on a previously developed age lexicon and did not report any performance metrics.
b RF: random forest.
c LogR: logistic regression.
d CPME: coupled projection matrix extraction.
e LLP: learning with label proportions.
f NR: not reported.
g SVC: support vector classifier.
a CNN: convolutional neural network.
c GRNN: graph recurrent neural network.
d DMT: deep multimodal multitask.
e mmDNN: multimodal deep neural network.
Assessing the performance differences between studies using traditional ML methods and those using deep learning or neural networks is challenging owing to variations in classification criteria (eg, different age groupings and different number of classification categories) and the variety of performance metrics reported. However, for both methods, higher performance was noted when the problem was framed as a binary or ternary classification than as a larger multinomial classification.
Studies Using Previously Developed Methods
Among the 74 included studies, there were 23 (31%) studies in which the detection of gender or age was secondary to their research, and previously developed methods were used to detect the demographic information of their cohort. Of the 23 studies, 13 (57%) used open-source models, and 10 (43%) used off-the-shelf software. More details about each study are given in the subsequent sections.
Open-Source Models
Of the 13 studies that used open-source models, 3 (4%) [ 74 , 99 , 100 ] drew upon an extant model [ 141 ] that used a predictive lexicon for the multiclass classification of age or gender for their applications. None of these studies created a validation corpus to assess the performance of the system, which was originally reported as 89.9% accuracy for gender and 0.84 Pearson correlation coefficient for age. One (1%) study [ 118 ] used the same text-based model [ 141 ] and an image model [ 142 ] to determine the age and gender of their cohort. When tested against their gold-standard corpus of self-reports from profile descriptions, they found that the imaging model performed best for gender (accuracy=90%-92%), whereas textual features gave the best results for age (accuracy=60%). A total of 3 (4%) studies [ 78 , 91 , 114 ] used demographer [ 115 , 139 , 143 ] for gender predictions, with 1 (33%) study [ 91 ] evaluating the performance against a set of users who had self-reported their gender in a survey, finding an F 1 -score of 0.869 for women and 0.770 for men. A total of 2 (3%) studies [ 61 , 62 ] used an ensemble classifier of previously developed models, with a reported accuracy of 0.83 and an F 1 -score of 0.83 [ 122 ]. Two (3%) other studies [ 67 , 120 ] used M3 [ 112 ] to detect gender and age, with 1 (50%) study validating the performance using a manually labeled data set, finding an accuracy of 95.9% and an F 1 -score of 0.957 for gender and an accuracy of 77.6% and an F 1 -score of 0.731 for age. One (1%) study [ 56 ] used Deep EXpectation of apparent age [ 144 ] for age and gender detection, which reported a validation error of 3.96 years for age and an 88% accuracy for gender. One (1%) study [ 98 ] used the rOPenSci gender package, and no assessment of performance was reported.
Off-the-Shelf Software
In the 10 studies that used off-the-shelf software, Face ++ was the most common software, being used in 6 (60%) studies [ 63 , 77 , 88 , 97 , 109 , 119 ]. The remaining studies used DemographicsPro [ 59 , 60 ], Microsoft Face API [ 84 ], and RapidMiner [ 103 ].
In 4 (40%) [ 88 , 97 , 103 , 109 ] of the 10 studies, no validation of performance was carried out, and a further 2 (20%) studies simply reported that DemographicsPro requires 95% confidence to make an estimation [ 59 , 60 ]. Other studies (n=4, 40%) compared with manual annotation and identified an accuracy of 82.8% for age using Face ++ [ 77 ], 68% for strict age groups, or 83% if the age groupings were relaxed [ 63 ]. The performance for age using Microsoft Face API was measured at 0.895 Gwet agreement coefficient (AC) [ 84 ], when compared with manually labeled data sets.
For gender, the studies (2/10, 20%) that measured performance against their own gold-standard labeled set of users recorded accuracies of 94.4% [ 77 ] or 88% [ 63 ] using Face ++. Other studies (3/10, 30%) [ 88 , 97 , 109 ] reported a confidence level of 95% +0.015 or –0.015 using Face ++ for gender prediction.
Only 1 (10%) [ 119 ] of the 10 studies went beyond manual annotation to create a gold standard and used multiple search techniques to manually verify age and gender, including LinkedIn profiles, electoral roll listings, personal websites, Twitter descriptions, and Twitter profile images. In this study, Face++ accuracy for age was reported as 40.4%, and Face++ accuracy for gender was reported as 44.8% (with a valid image accuracy of 32.5% for age and 87.7% for gender), and crowdsourcing annotation accuracy for age was 60.8% and for gender was 86.4% (with valid image accuracy of 56.1% for age and 93.9% for gender).
Principal Findings
In this review, we aimed to provide an overview of recent ML methods used to predict the gender and age of Twitter users, as these are key demographics for epidemiology. Our review indicates that both tasks have been popular, but the identification of gender has received more attention than the identification of age. However, no de facto standards for research (ie, data collection and evaluation) have emerged, resulting in a large number of heterogeneous studies that are not directly comparable. Thus, it is not straightforward to conclude where the state-of-the-art stands for these tasks.
Our review found evidence of potential bias that impacts the quality and representativeness of the data used in the studies. One prevalent source of bias lies in the data collection and labeling processes. For instance, some studies may introduce systemic bias through the use of imprecise labeling methods such as name matching for labeling Twitter users’ gender. This approach can lead to mislabeling, especially for individuals with names that are culturally diverse or androgynous and introduce inaccuracies into the training data. Another problem is the introduction of sampling bias through the use of artificially balanced data sets, creating an unrepresentative sample of the Twitter population, which, in reality, has a skewed distribution, with certain age and gender groups being more prevalent than others.
It is important to address and limit these biases because when ML models are trained on biased data, they tend to replicate and amplify these biases in their predictions [ 145 ].
The prediction of demographic information is an important task to address to fully realize the potential advantages of using social media data, such as those of using Twitter data in health-related research. In the United States, the National Institute of Health has committed to including women participants in clinical studies and including sex as a biological variable, finding that the disaggregation of data by sex will allow for sex-based comparisons of results to identify any sex-based differences. A recent review [ 146 ] found that this disaggregation in the development of ML models led to the discovery of sex-based differences that improved the model performance for sex-specific cohorts. Age is also important, as it can correlate and be a factor in the course and progression of disease [ 146 ] or the effects of medication [ 147 ]. Given the significance of this information, accurate and reproducible models must be developed. One way to ensure the reproducibility of models is for researchers to make data and codes available, including annotation guidelines. In addition to model performance, studies that create annotated corpora should report annotator agreement measures to assess the quality of the corpora. Few of the included studies made their data or code available ( Multimedia Appendices 3 , 4 , and 6 ).
A particular difficulty when comparing different systems comes from a lack of a gold standard that can be used to compare the systems. Some studies created their own corpora, collecting data randomly or based on keywords relevant to their studies. Others reused data sets from prior studies or shared tasks. Although outside the scope of this review, there have been shared tasks that aim to advance research through competition, focusing on gender and age prediction. A longstanding shared task focused on author profiling was hosted at the PAN workshop of CLEF [ 123 - 129 ]. More recently, Social Media Mining for Health (SMM4H), 2022, included 2 tasks for age detection, releasing new annotated corpora for the tasks [ 148 ]; several researchers reported using the corpora from these shared tasks. Testing and reporting performance metrics against these publicly available data sets, without alteration, would provide a comparable metric of different approaches. However, although reusing annotated corpora provides quick access to labeled data, it does have some limitations, including data loss over time as users delete their tweets, which not only reduces the size of the data but also can result in a data imbalance in the corpus.
A summary of our recommendations to reduce some potential bias in the data and improve the classification, reproducibility, and validation of the ML methods used can be found in Figure 2 .

Gender Prediction
Almost all the included studies approached the gender prediction task as a binary classification task, identifying a user as either male or female. We note that even when focusing on binary gender classification, which is the prevalent approach, the task of gender prediction on Twitter could be better characterized as a multinomial classification task: given a user account, the classifier should return male, female, or nonpersonal . The last label (nonpersonal) can account for Twitter users representing organizations or bots. Although some studies attempted to identify and exclude nonpersonal accounts as a preprocessing step, other studies developed their systems using previously annotated data sets that were exclusively labeled as male or female users or removed nonpersonal accounts during annotation before training and testing. It is unknown how well these systems would perform when extended to unseen data that may contain nonpersonal accounts.
Excluding nonpersonal accounts, the ratio of male users to female users in the training data set is also important, as it should mimic the natural distribution of Twitter users, estimated to be 31.5% female users and 68.5% male users as of January 2021 [ 149 ]. However, some authors biased their collections using unconventional methods of collection or using artificially balanced data sets. The most conventional method to collect a set of Twitter accounts is to query for any tweet mentioning functional words without semantic meaning such as of , the , or and from the Twitter API. Whereas collecting Twitter users using functional or neutral keywords, a given language, or geographic areas resulted in a male:female ratio close to the ratio naturally observed on Twitter, other choices resulted in collections with different ratios. Such changes in ratios could have improved (or deteriorated) the training of the authors’ classifiers and biased their evaluations, which did not reflect the performance of their approach on a random sample of Twitter users.
All studies treated gender as a binary determination of male or female. Although some referenced the limitation of this approach, they opted to use these designations given the need to align their data with outside resources, such as the US census or social security administration data. We note that gender, unlike biological sex, is not necessarily binary as it is a social construct and has been shown to influence a person’s use of health care, interactions, therapeutic responses, disease perceptions, and decision-making [ 150 ]; this underlies the importance of expanding the efforts of classification beyond binary to improve accuracy and avoid misinterpreting results.
Age Prediction
The age prediction task generally had a lower performance than the gender prediction task. This was true for studies that developed their own models as well as those that used open-source or off-the-shelf software. This may be because most studies approached age prediction as a multiclass classification task. The proxies used, such as language, names, networks, or images, may have limited predictive value for age. In addition, the distribution of Twitter users means that any data set will be inherently imbalanced, providing few training examples for age groups at the tail end of the distribution. This data imbalance may lead to too few instances of the minority classes to effectively train the classifier. For classification models based on images, poor performance for age may be unsurprising given that it can be difficult for humans to discern age from a single image. In addition, photos may be subject to photo editing or enhancement or may not be a recent photograph of the user. Because of a lack of error analysis reports in the included studies, it is difficult to determine the source of the classification difficulty for age.
Performance aside, the fact that the number and range of age groups vary across studies suggests that a classification approach is not generalizable to all research applications. Identifying the exact age, rather than age groups, can generalize to applications that do not align with predefined groupings of binary or multiclass models; however, using high-precision rules to extract self-reports of exact age from the user’s profile metadata had been shown not to scale. As we worked on this study, we noted that none of the reviewed systems opted for extracting the exact age. To test the feasibility and utility of a generalizable system that extracts the exact age from a tweet in a user’s timeline using deep learning methods, separate from this study, our group developed a classification and extraction pipeline using the RoBERTa-Large model and a rule-based extraction model [ 151 ]. The system was trained and tested on 11,000 annotated tweets. The classification of tweets mentioning an age achieved an F 1 -score of 0.93, and the extraction of age from these tweets achieved an F 1 -score of 0.86. From a collection of 245,947 users, age was extracted for 54% using REPORTage. A shared task for the classification task ran at the SMM4H 2022 workshop, and we released the annotated data set. We did not include our approach in the scoping review, as there were no comparable systems published before the release of the exact age extraction approach as part of the SMM4H 2022 shared task.
Potential Bias of Differing Methods
The limitations of using names to distinguish between genders may promote bias, particularly if the names used for training do not represent the ethnic diversity of the population, and some cultures may have more unisex names than others, which cannot be used to distinguish genders. There can be a high degree of uncertainty for many users for whom gender cannot be classified by name; estimates by Sloan et al [ 152 ] are that 52% of users will be unclassified using this method. However, studies have suggested that the classifications made may be relatively accurate given that the data from UK Twitter demonstrates a high level of agreement with the UK census data [ 153 ]. Furthermore, when used alone, this heuristic may label some organization accounts, such as PAUL_BAKERY, as a person.
Relying on self-declarations may be prone to bias as well. For example, younger people are more likely to profess their age than older adults, as age may be more important to them. With respect to gender pronouns, these may be more likely to be declared by those in some occupations or age groups. Indeed, there may also be other biases to self-declarations of data based on culture, background, social class, or country of origin or residence.
Using users’ profile images for gender and age identification is challenging. Not all Twitter users provide a picture of themselves, with many opting for pictures of their pets, objects, children, scenery, or even celebrities. Identifying the gender and age of even those with pictures of themselves can be problematic if the quality of the pictures is poor, the pictures contain more than 1 face, or the pictures are not recent, particularly for predicting age. A comparison of systems using images to predict demographics [ 154 ] measured not only the accuracy in identifying age and gender but also the percentage of images in which a face could be detected, finding that only approximately 30% of Twitter users had a single detectable face.
Methods to filter out organizations in the studies included removing accounts with a large number of followers [ 71 ] or explicitly searching for organizations by matching username terms linked to economic activities, such as restaurant and hotel [ 49 ]. These methods remove accounts that do not represent a single user. However, they do not remove bots. Although one of the studies created a classifier to detect bots, the filtering of bots was limited to those identified in manual annotation, by simple heuristics, or nonexistent in many studies ( Multimedia Appendix 5 ).
Validation of Age and Gender Proxies
For cases where age or gender are estimated, it is necessary to conduct validation exercises whereby the data are compared with a gold-standard data set to establish accuracy levels. For example, 1 study [ 119 ] that used off-the-shelf software also created a manually annotated gold-standard data set for measuring accuracy. This study found that although the accuracy of crowdsourcing was higher than that of software, the accuracy was only approximately 60% for age. This puts into question the use of manual annotations alone as a gold standard.
The most reliable way of generating a gold standard is to obtain the information directly from the user. This may be done in the form of direct correspondence with the user, such as messaging via social media or, the other way around, requesting Twitter handles in surveys that collect demographic data. Other methods for validation, such as manual extraction, may be less rigorous. However, these methods can be improved by multiple independent annotators, using experienced teams.
External validation of the model is also a vital step to assess how the model will perform on unseen data [ 155 , 156 ]. In a validation on a second data set, Yang et al [ 117 ] found that performance dropped in all but 2 of their models, stressing the importance of benchmarking existing systems on a targeted corpus. This step is equally important when using existing systems, so a range of expected performances can be reported and used in any analysis of the output.
In addition to the potential biases reported earlier, predicting the age and gender of Twitter users has some potential limitations that should be considered and, when possible, addressed to limit their effects. As evidenced by the performance results of the included studies, determining the precise age or age group of Twitter users solely based on their Twitter profiles and tweet content can be challenging. Although methods to extract a user’s self-reported age can be executed with high precision [ 151 ], predicting age, especially for more specific age groups, remains a complex task. Another limitation to consider is the potential for users to misrepresent their reported age or gender, which can introduce inaccuracies and affect the reliability of predictions based on user-supplied data. This phenomenon is not unique to Twitter and has been identified in other data sources such as surveys [ 157 , 158 ]. Many of the included studies used self-reported data to label their training data; therefore, any potential misrepresentations could be approached as a noisy label problem. There are numerous methods that can be used to manage the effect of label noise on classification models, such as distance learning or ensemble methods [ 159 , 160 ]. Furthermore, it is important to effectively address potential noise and uncertainty when using the output data for secondary analysis. Statistical techniques that can handle imprecise or uncertain data, such as Bayesian inference or fuzzy logic, can be valuable in this context. Using these methods, the analysis can better account for uncertain predictions, leading to more robust and reliable results. Finally, users’ age changes over time, and their profiles may not be updated accordingly, or the age tweet may be from an earlier year and not reflect their current age. Researchers should ensure that the users’ labeled age is contemporaneous with the other data included in the prediction model. Predicting the age and gender of Twitter users provides valuable insights, and most identified limitations presented by the data can be mitigated.
Ethical Considerations
Several studies have shown that social media users generally do not have concerns about their data being used for research or even have favorable opinions about it [ 161 , 162 ]. However, the ethical frameworks for the use of these data are still being developed [ 163 - 165 ], and institutional review boards may deem the use of publicly available data, such as those collected from Twitter, as exempt from human participant research; however, it is incumbent on the researcher to consult with their institutional review boards or equivalent ethical committees to obtain such exemptions [ 165 ]. Although the data are publicly available, it is important to carefully consider potential ethical implications when predicting the age and gender of Twitter users. This process may raise privacy concerns, particularly when publishing data that may be considered sensitive, necessitating the protection of user identities and the anonymization of data to prevent reidentification [ 166 ]. Anonymizing the data may include removing user identifiers, modifying the tweet text, or generating synthetic tweets [ 165 ]. In addition, automated methods for predicting user age or gender have limitations and may result in misclassifications. Transparency regarding the limitations of the methods, algorithms, and data sources used in age and gender prediction are essential to report so that any use of these methods or data in secondary analysis can take such limitations into account. Although the prediction of age and gender may present some potential ethical concerns, it is important to recognize that there are also benefits to the use of these data for health research that can outweigh these concerns, such as eliciting insights into disease prevalence, patterns, and variations or distinguishing health behaviors and attitudes across different subgroups.
Limitations
It is unlikely that we have identified all studies using off-the-shelf software, as we did not search for specific named software, but part of our remit was to identify the array of software used. We did not limit our inclusion to only studies that developed their own software; therefore, we have included studies that used proprietary software. These software products do not publish their methodologies; therefore, we are unable to directly compare these approaches with others.
We also included studies for which the prediction of age and gender was secondary to the primary focus of their study. These studies either used proprietary software, previously developed methods, or developed limited methods to predict demographic information. In general, these studies did not report the performance of their prediction methods on their data sets. Although some reported the original performance metrics of the methods used, it cannot be assumed that these methods will perform similarly across all data.
Conclusions
The prediction of demographic data, such as age and gender, is an important step in increasing the value and application of social media data. Many methods have been reported in the literature with differing degrees of success. Although we sought to explore whether deep learning approaches would advance the performance for these tasks as they have been shown to do for other natural language processing tasks, many of the included studies used traditional ML methods. Although only explored by a handful of studies, deep learning methods appear to perform well for the prediction of a user’s gender or age. However, direct comparison of the published methods was impossible, as different test sets were used in the studies. This highlights the need for recently developed, publicly available gold-standard corpora, such as those released for shared tasks such as SMM4H or PAN-CLEF, to have unbiased data and baseline metrics to compare different approaches going forward.
Acknowledgments
This work was supported by the National Institutes of Health (NIH) National Library of Medicine (NLM) under grant NIH-NLM R01LM011176. The NIH NLM funded this research but was not involved in the design or conduct of the study; collection, management, analysis, or interpretation of the data; preparation, review, or approval of the manuscript; or the decision to submit the manuscript for publication.
Data Availability
The included studies are available on the web. The search strategy and extracted data on included studies are available in Multimedia Appendices 2 - 6 .
Authors' Contributions
SG, KO, and GGH devised the study and identified data for extraction. SG created and executed the search strategy and created the initial draft of the manuscript. SG and KO were responsible for study selection. All the authors were responsible for data extraction, summarization, and discussion. KO synthesized all data and created all tables. All the authors commented on and edited the manuscript. KO provided the final version of the manuscript. All the authors contributed to the final draft of the manuscript.
Conflicts of Interest
None declared.
PRISMA-ScR (Preferred Reporting Items for Systematic Reviews and Meta-Analyses Extension for Scoping Reviews) checklist.
Search strategies and results for individual databases.
Extracted data from the included studies predicting gender.
Extracted data from the included studies predicting age.
Information on the identification and removal of nonpersonal or bot accounts from the data set. Features used for annotation or prediction of gender or age.
Details of corpora created in the included studies and their reported availability.
- Real-world evidence. U.S. Food and Drug Administration. URL: https://www.fda.gov/science-research/science-and-research-special-topics/real-world-evidence [accessed 2023-03-30]
- Alessa A, Faezipour M. A review of influenza detection and prediction through social networking sites. Theor Biol Med Model. Feb 01, 2018;15(1):2. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Bisanzio D, Kraemer MU, Bogoch II, Brewer T, Brownstein JS, Reithinger R. Use of Twitter social media activity as a proxy for human mobility to predict the spatiotemporal spread of COVID-19 at global scale. Geospat Health. Jun 15, 2020;15(1). [ FREE Full text ] [ CrossRef ] [ Medline ]
- Magge A, Tutubalina E, Miftahutdinov Z, Alimova I, Dirkson A, Verberne S, et al. DeepADEMiner: a deep learning pharmacovigilance pipeline for extraction and normalization of adverse drug event mentions on Twitter. J Am Med Inform Assoc. Sep 18, 2021;28(10):2184-2192. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Nikfarjam A, Sarker A, O'Connor K, Ginn R, Gonzalez G. Pharmacovigilance from social media: mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. J Am Med Inform Assoc. May 2015;22(3):671-681. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Guntuku SC, Sherman G, Stokes DC, Agarwal AK, Seltzer E, Merchant RM, et al. Tracking mental health and symptom mentions on twitter during COVID-19. J Gen Intern Med. Sep 2020;35(9):2798-2800. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Ma L, Wang Y. Constructing a semantic graph with depression symptoms extraction from Twitter. In: Proceedings of the IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB). Presented at: CIBCB 2019; July 9-11, 2019; Siena, Italy. [ CrossRef ]
- Bauermeister JA, Zimmerman MA, Johns MM, Glowacki P, Stoddard S, Volz E. Innovative recruitment using online networks: lessons learned from an online study of alcohol and other drug use utilizing a web-based, respondent-driven sampling (webRDS) strategy. J Stud Alcohol Drugs. Sep 2012;73(5):834-838. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Weissenbacher D, Flores J, Wang Y, O'Connor K, Rawal S, Stevens R, et al. Automatic cohort determination from Twitter for HIV prevention amongst Black and Hispanic men. AMIA Jt Summits Transl Sci Proc. 2022.:504-513. [ FREE Full text ] [ Medline ]
- Twitter API. Twitter. URL: https://developer.twitter.com/en/docs/twitter-api [accessed 2023-03-30]
- Sinnenberg L, Buttenheim AM, Padrez K, Mancheno C, Ungar L, Merchant RM. Twitter as a tool for health research: a systematic review. Am J Public Health. Jan 2017;107(1):e1-e8. [ CrossRef ] [ Medline ]
- Gustafson DL, Woodworth CF. Methodological and ethical issues in research using social media: a metamethod of Human Papillomavirus vaccine studies. BMC Med Res Methodol. Dec 02, 2014;14:127. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Beck C, McSweeney JC, Richards KC, Roberson PK, Tsai PF, Souder E. Challenges in tailored intervention research. Nurs Outlook. Mar 2010;58(2):104-110. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Rimer BK, Kreuter MW. Advancing tailored health communication: a persuasion and message effects perspective. J Commun. Aug 2006;56(s1):S184-S201. [ CrossRef ]
- Hinds J, Joinson AN. What demographic attributes do our digital footprints reveal? A systematic review. PLoS One. Nov 28, 2018;13(11):e0207112. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Dredze M. How social media will change public health. IEEE Intell Syst. Jul 2012;27(4):81-84. [ FREE Full text ] [ CrossRef ]
- Golder S, Stevens R, O'Connor K, James R, Gonzalez-Hernandez G. Methods to establish race or ethnicity of twitter users: scoping review. J Med Internet Res. Apr 29, 2022;24(4):e35788. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Bour C, Ahne A, Schmitz S, Perchoux C, Dessenne C, Fagherazzi G. The use of social media for health research purposes: scoping review. J Med Internet Res. May 27, 2021;23(5):e25736. [ FREE Full text ] [ CrossRef ] [ Medline ]
- van Oosterhout R, de Boer AR, Maas AH, Rutten FH, Bots ML, Peters SA. Sex differences in symptom presentation in acute coronary syndromes: a systematic review and meta-analysis. J Am Heart Assoc. May 05, 2020;9(9):e014733. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Trevisan C, Noale M, Prinelli F, Maggi S, Sojic A, Di Bari M, et al. EPICOVID19 Working Group. Age-related changes in clinical presentation of Covid-19: the EPICOVID19 web-based survey. Eur J Intern Med. Apr 2021;86:41-47. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Brady E, Nielsen MW, Andersen JP, Oertelt-Prigione S. Lack of consideration of sex and gender in COVID-19 clinical studies. Nat Commun. Jul 06, 2021;12(1):4015. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Tannenbaum C, Ellis RP, Eyssel F, Zou J, Schiebinger L. Sex and gender analysis improves science and engineering. Nature. Nov 2019;575(7781):137-146. [ CrossRef ] [ Medline ]
- Amiri P, Mohammadzadeh-Naziri K, Abbasi B, Cheraghi L, Jalali-Farahani S, Momenan AA, et al. Smoking habits and incidence of cardiovascular diseases in men and women: findings of a 12 year follow up among an urban Eastern-Mediterranean population. BMC Public Health. Aug 05, 2019;19(1):1042. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Rosselli M, Ermini E, Tosi B, Boddi M, Stefani L, Toncelli L, et al. Gender differences in barriers to physical activity among adolescents. Nutr Metab Cardiovasc Dis. Aug 28, 2020;30(9):1582-1589. [ CrossRef ] [ Medline ]
- Chen SL, Lee WL, Liang T, Liao IC. Factors associated with gender differences in medication adherence: a longitudinal study. J Adv Nurs. Sep 2014;70(9):2031-2040. [ CrossRef ] [ Medline ]
- Krueger K, Botermann L, Schorr SG, Griese-Mammen N, Laufs U, Schulz M. Age-related medication adherence in patients with chronic heart failure: a systematic literature review. Int J Cardiol. Apr 01, 2015;184:728-735. [ CrossRef ] [ Medline ]
- Auxier B, Anderson M. Social media use in 2021. Pew Research Center. Apr 7, 2021. URL: https://www.pewresearch.org/internet/2021/04/07/social-media-use-in-2021/ [accessed 2021-12-09]
- World population prospects - population division - United Nations. United Nations Department of Economic and Social Affairs Population Division. URL: https://population.un.org/wpp/ [accessed 2023-07-28]
- Mislove A, Lehmann S, Ahn YY, Onnela JP, Rosenquist J. Understanding the demographics of Twitter users. Proc Int AAAI Conf Web Soc Media. Aug 03, 2021;5(1):554-557. [ CrossRef ]
- Fink C, Kopecky J, Morawski M. Inferring gender from the content of tweets: a region specific example. Proc Int AAAI Conf Web Soc Media. Aug 03, 2021;6(1):459-462. [ CrossRef ]
- Alowibdi JS, Buy UA, Yu P. Language independent gender classification on Twitter. In: Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. Presented at: ASONAM '13; August 25-28, 2013; Niagara Falls, ON.
- Chen L, Qian T, Zhu P, You Z. Learning user embedding representation for gender prediction. In: Proceedings of the IEEE 28th International Conference on Tools with Artificial Intelligence (ICTAI). Presented at: ICTAI 2016; November 6-8, 2016; San Jose, CA. [ CrossRef ]
- Culotta A, Ravi NK, Cutler J. Predicting the demographics of Twitter users from website traffic data. In: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. Presented at: AAAI'15; January 25-30, 2015; Austin, TX. URL: https://dl.acm.org/doi/abs/10.5555/2887007.2887018 [ CrossRef ]
- Sloan L, Morgan J, Burnap P, Williams M. Who tweets? Deriving the demographic characteristics of age, occupation and social class from Twitter user meta-data. PLoS One. 2015;10(3):e0115545. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Oktay H, Firat A, Ertem Z. Demographic breakdown of Twitter users: an analysis based on names. In: Proceedings of the Academy of Science and Engineering (ASE). Presented at: ASE'14; September 15-19, 2014; Västerås, Sweden. URL: https://www.researchgate.net/publication/315538705_Demographic_Breakdown_of_Twitter_Users_An_analysis_based_on_names
- Nguyen D, Gravel R, Trieschnigg D, Meder T. "How old do you think I am?" A study of language and age in Twitter. Proc Int AAAI Conf Web Soc Media. Aug 03, 2021;7(1):439-448. [ CrossRef ]
- Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space. arXiv. Preprint posted online January 16, 2013. [ CrossRef ]
- Mikolov T, Sutskever I, Chen K, Corrado G, Dean J. Distributed representations of words and phrases and their compositionality. In: Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2. Presented at: NIPS'13; December 5-10, 2013; Lake Tahoe, Nevada. URL: https://dl.acm.org/doi/proceedings/10.5555/2999792
- Tricco AC, Lillie E, Zarin W, O'Brien KK, Colquhoun H, Levac D, et al. PRISMA extension for Scoping Reviews (PRISMA-ScR): checklist and explanation. Ann Intern Med. Oct 02, 2018;169(7):467-473. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Umar A, Bashir SA, Abdullahi MB, Adebayo OS. Comparative study of various machine learning algorithms for tweet classification. i-Manager J Comput Sci. 2019;6(4):12. [ FREE Full text ]
- Amir-Behghadami M, Janati A. Population, Intervention, Comparison, Outcomes and Study (PICOS) design as a framework to formulate eligibility criteria in systematic reviews. Emerg Med J. Jun 2020;37(6):387. [ CrossRef ] [ Medline ]
- Bramer WM, Giustini D, Kramer BM. Comparing the coverage, recall, and precision of searches for 120 systematic reviews in Embase, MEDLINE, and Google Scholar: a prospective study. Syst Rev. Mar 01, 2016;5:39. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Kugley S, Wade A, Thomas J, Mahood Q, Jørgensen AM, Hammerstrøm K, et al. Searching for studies: a guide to information retrieval for Campbell systematic reviews. Campbell Syst Rev. Feb 13, 2017;13(1):1-73. [ CrossRef ]
- Lefebvre C, Glanville J, Briscoe S, Littlewood A, Marshall C, Metzendorf MI, et al. Technical Supplement to Chapter 4: searching for and selecting studies. In: Higgins JP, Thomas J, Chandler J, Cumpston MS, Li T, Page MJ, et al, editors. Cochrane Handbook for Systematic Reviews of Interventions Version 6.3. London, UK. The Cochrane Collaboration; 2022.
- Booth A. How much searching is enough? Comprehensive versus optimal retrieval for technology assessments. Int J Technol Assess Health Care. Oct 2010;26(4):431-435. [ CrossRef ] [ Medline ]
- Briscoe S, Nunns M, Shaw L. How do Cochrane authors conduct web searching to identify studies? Findings from a cross-sectional sample of Cochrane Reviews. Health Info Libr J. Dec 2020;37(4):293-318. [ CrossRef ] [ Medline ]
- Stansfield C, Dickson K, Bangpan M. Exploring issues in the conduct of website searching and other online sources for systematic reviews: how can we be systematic? Syst Rev. Nov 15, 2016;5(1):191. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Godin K, Stapleton J, Kirkpatrick SI, Hanning RM, Leatherdale ST. Applying systematic review search methods to the grey literature: a case study examining guidelines for school-based breakfast programs in Canada. Syst Rev. Oct 22, 2015;4:138. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Alessandra R, Gentile MM, Bianco DM. Who tweets in Italian? Demographic characteristics of twitter users. In: Petrucci A, Racioppi F, Verde R, editors. New Statistical Developments in Data Science. Cham, Switzerland. Springer; Aug 21, 2019.
- Alfayez A, Awwad Z, Kerr C, Alrashed N, Williams S, Al-Wabil A. Understanding gendered spaces using social media data. In: Meiselwitz G, editor. Social Computing and Social Media. Applications and Analytics. Cham, Switzerland. Springer; 2017.
- Arafat TA, Budi I, Mahendra R, Salehah DA. Demographic analysis of candidates supporter in Twitter during Indonesian presidential election 2019. In: Proceedings of the International Conference on ICT for Smart Society (ICISS). Presented at: ICISS 2020; November 19-20, 2020; Bandung, Indonesia. [ CrossRef ]
- Ardehaly EM, Culotta A. Co-training for demographic classification using deep learning from label proportions. In: Proceedings of the IEEE International Conference on Data Mining Workshops (ICDMW). Presented at: ICDMW 2017; November 18-21, 2017; New Orleans, LA. URL: https://ieeexplore.ieee.org/document/8215778 [ CrossRef ]
- Ardehaly EM, Culotta A. Learning from noisy label proportions for classifying online social data. Soc Netw Anal Mining. Nov 27, 2017;8(1). [ CrossRef ]
- Baxevanakis S, Gavras S, Mouratidis D, Kermanidis KL. A machine learning approach for gender identification of Greek tweet authors. In: Proceedings of the 13th ACM International Conference on PErvasive Technologies Related to Assistive Environments. Presented at: PETRA '20; June 30-July 3, 2020; Corfu, Greece. URL: https://dl-acm-org.proxy.library.upenn.edu/doi/10.1145/3389189.3397992 [ CrossRef ]
- Bayot RK, Gonçalves T. Age and gender classification of Tweets using convolutional neural networks. In: Proceedings of the Third International Conference, MOD 2017. Presented at: MOD 2017; September 14-17, 2017; Volterra, Italy. [ CrossRef ]
- Brandt J, Buckingham K, Buntain C, Anderson W, Ray S, Pool JR, et al. Identifying social media user demographics and topic diversity with computational social science: a case study of a major international policy forum. J Comput Soc Sci. Jan 07, 2020;3:167-188. [ CrossRef ]
- Bsir B, Zrigui M. Enhancing deep learning gender identification with gated recurrent units architecture in social text. Computacion y Sistemas. Sep 30, 2018;22(3):757-766. [ CrossRef ]
- Bsir B, Zrigui M. Document model with attention bidirectional recurrent network for gender identification. In: Proceedings of the 15th International Work-Conference on Artificial Neural Networks. Presented at: IWANN 2019; June 12-14, 2019; Gran Canaria, Spain. [ CrossRef ]
- Cavazos-Rehg PA, Zewdie K, Krauss MJ, Sowles SJ. "No high like a brownie high": a content analysis of edible marijuana tweets. Am J Health Promot. May 2018;32(4):880-886. [ CrossRef ] [ Medline ]
- Cavazos-Rehg PA, Krauss MJ, Costello SJ, Kaiser N, Cahn ES, Fitzsimmons-Craft EE, et al. "I just want to be skinny.": a content analysis of tweets expressing eating disorder symptoms. PLoS One. Jan 16, 2019;14(1):e0207506. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Cesare N, Dwivedi P, Nguyen Q, Nsoesie EO. Use of social media, search queries, and demographic data to assess obesity prevalence in the United States. Palgrave Commun. Sep 17, 2019;5(1):106. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Cesare N, Nguyen Q, Grant C, Nsoesie EO. Social media captures demographic and regional physical activity. BMJ Open Sport Exerc Med. Jul 14, 2019;5(1):e000567. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Chakraborty A, Messias J, Benevenuto F, Ghosh S, Ganguly N, Gummadi K. Who makes trends? Understanding demographic biases in crowdsourced recommendations. In: Proceedings of the International AAAI Conference on Web and Social Media. Presented at: ICWSM-17; Montreal, Quebec; May 15-18, 2017. [ CrossRef ]
- Chamberlain BP, Humby C, Deisenroth MP. Probabilistic inference of Twitter users’ age based on what they follow. In: Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases (ECML PKDD 2017). Presented at: ECML PKDD 2017; September 18-22, 2017; Skopje, Macedonia. [ CrossRef ]
- Cheng JK, Fernandez A, Quindoza RG, Tan S, Cheng C. A model for age and gender profiling of social media accounts based on post contents. In: Neural Information Processing. New York City, NY. Springer International Publishing; 2018.
- Cornelisse J, Pillai RG. Age inference on Twitter using SAGE and TF-IGM. In: Proceedings of the 4th International Conference on Natural Language Processing and Information Retrieval. 2020. Presented at: NLPIR 2020; December 18-20, 2020; Seoul, Republic of Korea. [ CrossRef ]
- Duong V, Luo J, Pham P, Yang T, Wang Y. The ivory tower lost: how college students respond differently than the general public to the COVID-19 pandemic. In: Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM). Presented at: ASONAM 2020; December 7-10, 2020; The Hague, The Netherlands. [ CrossRef ]
- ElSayed S, Farouk M. Gender identification for Egyptian Arabic dialect in twitter using deep learning models. Egypt Inform J. Sep 2020;21(3):159-167. [ CrossRef ]
- Emmery C, Chrupała G, Daelemans W. Simple queries as distant labels for predicting gender on Twitter. In: Proceedings of the 3rd Workshop on Noisy User-generated Text. Presented at: NUT@EMNLP 2017; September 7, 2017; Copenhagen, Denmark. URL: https://github.com/facebookresearch/ [ CrossRef ]
- Garcia-Guzman R, Andrade-Ambriz YA, Ibarra-Manzano MA, Ledesma S, Gomez JC, Almanza-Ojeda DL. Trend-based categories recommendations and age-gender prediction for Pinterest and Twitter users. Appl Sci. Aug 28, 2020;10(17):5957. [ CrossRef ]
- Geng L, Zhang K, Wei X, Feng X. Soft biometrics in online social networks: a case study on Twitter user gender recognition. In: Proceedings of the IEEE Winter Applications of Computer Vision Workshops (WACVW). Presented at: WACVW 2017; March 24-31, 2017; Santa Rosa, CA. [ CrossRef ]
- Giannakopoulos O, Kalatzis N, Roussaki I, Papavassiliou S. Gender recognition based on social networks for multimedia production. In: Proceedings of the IEEE 13th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP). Presented at: IVMSP 2018; June 10-12, 2018; Aristi Village, Greece. [ CrossRef ]
- Guimaraes RG, Rosa RL, De Gaetano D, Rodriguez DZ, Bressan G. Age groups classification in social network using deep learning. IEEE Access. May 23, 2017;5:10805-10816. [ CrossRef ]
- Hasanuzzaman M, Dias G, Way A. Demographic word embeddings for racism detection on Twitter. In: Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Presented at: IJCNLP 2017; November 28-30, 2017; Taipei, Taiwan.
- Hashempour R. A deep learning approach to language-independent gender prediction on Twitter. In: Proceedings of the 2019 Workshop on Widening NLP. Presented at: 2019 Workshop on Widening NLP; July 28, 2019; Florence, Italy. [ CrossRef ]
- Hirt R, Kühl N, Satzger G. Cognitive computing for customer profiling: meta classification for gender prediction. Electron Mark. Feb 21, 2019;29:93-106. [ CrossRef ]
- Huang X, Xing L, Dernoncourt F, Paul MJ. Multilingual Twitter corpus and baselines for evaluating demographic bias in hate speech recognition. In: Proceedings of the Twelfth Language Resources and Evaluation Conference. Presented at: LREC 2020; May 11-16, 2020; Marseille, France.
- Huang X, Smith MC, Jamison AM, Broniatowski DA, Dredze M, Quinn SC, et al. Can online self-reports assist in real-time identification of influenza vaccination uptake? A cross-sectional study of influenza vaccine-related tweets in the USA, 2013-2017. BMJ Open. Jan 15, 2019;9(1):e024018. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Hussein S, Farouk M, Hemayed E. Gender identification of Egyptian dialect in twitter. Egypt Inform J. Jul 2019;20(2):109-116. [ CrossRef ]
- Jurgens D, Tsvetkov Y, Jurafsky D. Writer profiling without the writer’s text. In: Proceedings of the 9th International Conference, SocInfo 2017. Presented at: SocInfo 2017; September 13-15, 2017; Oxford, UK. [ CrossRef ]
- Kang Y, Wang Y, Zhang D, Zhou L. The public's opinions on a new school meals policy for childhood obesity prevention in the U.S.: a social media analytics approach. Int J Med Inform. Jul 2017;103:83-88. [ CrossRef ] [ Medline ]
- Khandelwal A, Swami S, Akhtar SS, Shrivastava M. Gender prediction in English-Hindi code-mixed social media content: corpus and baseline system. Computacion y Sistemas. 2018;22(3). [ FREE Full text ] [ CrossRef ]
- Kim SM, Xu Q, Qu L, Wan S, Paris C. Demographic inference on Twitter using recursive neural networks. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Presented at: ACL 2017; July 30-August 4, 2017; Vancouver, Canada. [ CrossRef ]
- Kostakos P, Pandya A, Kyriakouli O, Oussalah M. Inferring demographic data of marginalized users in Twitter with computer vision APIs. In: Proceedings of the European Intelligence and Security Informatics Conference (EISIC). Presented at: EISIC 2018; October 24-25, 2018; Karlskrona, Sweden. [ CrossRef ]
- Ljubešić N, Fišer D, Erjavec T. Language-independent gender prediction on Twitter. In: Proceedings of the Second Workshop on NLP and Computational Social Science. Presented at: NLP+CSS 2017; August 3, 2017; Vancouver, Canada. [ CrossRef ]
- López-Monroy AP, González FA, Solorio T. Early author profiling on Twitter using profile features with multi-resolution. Expert Syst Appl. Feb 2020;140:112909. [ CrossRef ]
- Markov I, Gómez-Adorno H, Posadas-Durán JP, Sidorov G, Gelbukh A. Author profiling with Doc2vec neural network-based document embeddings. In: Proceedings of the 15th Mexican International Conference on Artificial Intelligence. Presented at: MICAI 2016; October 23-28, 2016; Cancún, Mexico. [ CrossRef ]
- Messias J, Vikatos P, Benevenuto F. White, man, and highly followed: gender and race inequalities in Twitter. In: Proceedings of the International Conference on Web Intelligence. Presented at: WI '17; August 23-26, 2017; Leipzig, Germany. [ CrossRef ]
- Miura R, Hirota M, Kato D, Araki T, Endo M, Ishikawa H. Predicting user gender on social media sites using geographical information. In: Proceedings of the 10th International Conference on Management of Digital EcoSystems. Presented at: MEDES '18; September 25-28, 2018; Tokyo, Japan. [ CrossRef ]
- Morgan-Lopez AA, Kim AE, Chew RF, Ruddle P. Predicting age groups of Twitter users based on language and metadata features. PLoS One. 2017;12(8):e0183537. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Mueller A, Wood-Doughty Z, Amir S, Dredze M, Lynn Nobles A. Demographic representation and collective storytelling in the me too Twitter hashtag activism movement. Proc ACM Hum Comput Interact. Apr 22, 2021;5(CSCW1):1-28. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Mukherjee S, Bala PK. Gender classification of microblog text based on authorial style. Inf Syst E Bus Manage. Mar 2, 2016;15(1):117-138. [ CrossRef ]
- Imuede J, Raborife M, Ranchod P. Sentiment analysis as an indicator to evaluate gender disparity on sexual violence tweets in South Africa. In: Proceedings of the International SAUPEC/RobMech/PRASA Conference. Presented at: International SAUPEC/RobMech/PRASA Conference; January 29-31, 2020; Cape Town, South Africa. [ CrossRef ]
- Pandya A, Oussalah M, Monachesi P, Kostakos P, Loven L. On the use of URLs and hashtags in age prediction of Twitter users. In: Proceedings of the IEEE International Conference on Information Reuse and Integration (IRI). Presented at: IEEE IRI 2018; July 6-9, 2018; Salt Lake City, UT. [ CrossRef ]
- Pandya A, Oussalah M, Monachesi P, Kostakos P. On the use of distributed semantics of tweet metadata for user age prediction. Future Gener Comput Syst. Jan 2020;102:437-452. [ CrossRef ]
- Pizarro J. Profiling bots and fake news spreaders at PAN’19 and PAN’20 : bots and gender profiling 2019, profiling fake news spreaders on Twitter 2020. In: Proceedings of the IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA). Presented at: DSAA 2020; October 6-9, 2020; Sydney, Australia. [ CrossRef ]
- Reis JC, Kwak H, An J, Messias J, Benevenuto F. Demographics of news sharing in the U.S. Twittersphere. In: Proceedings of the 28th ACM Conference on Hypertext and Social Media. Presented at: HT'17; July 4-7, 2017; Prague, Czech Republic. [ CrossRef ]
- Serfass DG. Assessing situations on social media: temporal, demographic, and personality influences on situation experience. Florida Atlantic University . 2016. URL: https://www.proquest.com/openview/6a5ca1b98806d5f3a2ce7e66e2f358cd/1?pq-origsite=gscholar&cbl=18750 [accessed 2023-03-30]
- Stevens R, Bonett S, Bannon J, Chittamuru D, Slaff B, Browne SK, et al. Association between HIV-related Tweets and HIV incidence in the United States: infodemiology study. J Med Internet Res. Jun 24, 2020;22(6):e17196. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Stevens RC, Brawner BM, Kranzler E, Giorgi S, Lazarus E, Abera M, et al. Exploring substance use Tweets of youth in the United States: mixed methods study. JMIR Public Health Surveill. Mar 26, 2020;6(1):e16191. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Swain S, Seeja KR. TWEESENT: a web application on sentiment analysis. In: Proceedings of the Second International Conference on Smart Innovations in Communications and Computational Sciences. 2019. Presented at: ICSICCS-2018; April 28-29, 2018; Indore, India. [ CrossRef ]
- Thelwall M, Thelwall S. Covid-19 tweeting in English: gender differences. Prof De La Inf. May 04, 2020;29(3). [ CrossRef ]
- Udayakumar S, Senadeera DC, Yamunarani S, Cheon NJ. Demographics analysis of Twitter users who tweeted on psychological articles and tweets analysis. Procedia Comput Sci. 2018;144:96-104. [ CrossRef ]
- van der Goot R, Ljubešić N, Matroos I, Nissim M, Plank B. Bleaching text: abstract features for cross-lingual gender prediction. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Presented at: ACL 2018; July 15-20, 2018; Melbourne, Australia. [ CrossRef ]
- Vashisth P, Meehan K. Gender classification using Twitter text data. In: Proceedings of the 31st Irish Signals and Systems Conference (ISSC). Presented at: ISSC 2020; June 11-12, 2020; Letterkenny, Ireland. [ CrossRef ]
- Verhoeven B, Škrjanec I, Pollak S. Gender profiling for Slovene Twitter communication: the influence of gender marking, content and style. In: Proceedings of the 6th Workshop on Balto-Slavic Natural Language Processing. Presented at: BSNLP 2017; April 4, 2017; Valencia, Spain. [ CrossRef ]
- Vicente M, Batista F, Carvalho JP. Gender detection of Twitter users based on multiple information sources. In: Kóczy L, Medina-Moreno J, Ramírez-Poussa E, editors. Interactions Between Computational Intelligence and Mathematics Part 2. Cham, Switzerland. Springer; Nov 03, 2018.
- Vijayaraghavan P, Vosoughi S, Roy D. Twitter demographic classification using deep multi-modal multi-task learning. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Presented at: ACL 2017; July 30-August 4, 2017; Vancouver, Canada. [ CrossRef ]
- Vikatos P, Messias J, Miranda M, Benevenuto F. Linguistic diversities of demographic groups in Twitter. In: Proceedings of the 28th ACM Conference on Hypertext and Social Media. Presented at: HT'17; July 4-7, 2017; Prague, Czech Republic. [ CrossRef ]
- Volkova S. Predicting demographics and affect in social networks. The Johns Hopkins University. Oct 2015. URL: https://jscholarship.library.jhu.edu/bitstream/handle/1774.2/39639/VOLKOVA-DISSERTATION-2015.pdf?sequence=1&isAllowed=y [accessed 2023-03-30]
- Wang Y, Feng Y, Luo J. Gender politics in the 2016 U.S. Presidential election: a computer vision approach. In: Proceedings of the 10th International Conference, SBP-BRiMS 2017. Presented at: SBP-BRiMS 2017; July 5-8, 2017; Washington, DC. [ CrossRef ]
- Wang Z, Hale S, Adelani DI, Grabowicz P, Hartman T, Flöck F, et al. Demographic inference and representative population estimates from multilingual social media data. In: Proceedings of the The World Wide Web Conference. Presented at: WWW '19; May 13-17, 2019; San Francisco, CA. [ CrossRef ]
- Wong SC, Teh PL, Cheng CB. How different genders use profanity on Twitter? In: Proceedings of the 2020 the 4th International Conference on Compute and Data Analysis. Presented at: ICCDA 2020; March 9-12, 2020; Silicon Valley, CA. [ CrossRef ]
- Wood-Doughty Z, Smith M, Broniatowski D, Dredze M. How does Twitter user behavior vary across demographic groups? In: Proceedings of the Second Workshop on NLP and Computational Social Science. Presented at: NLP+CSS 2017; August 3, 2017; Vancouver, Canada. [ CrossRef ]
- Wood-Doughty Z, Andrews N, Marvin R, Dredze M. Predicting Twitter user demographics from names alone. In: Proceedings of the Second Workshop on Computational Modeling of People’s Opinions, Personality, and Emotions in Social Media. Presented at: PEOPLES 2018; June 6, 2018; New Orleans, LA. [ CrossRef ]
- Xiang L, Sang J, Xu C. Demographic attribute inference from social multimedia behaviors: a cross-OSN approach. In: Proceedings of the 23rd International Conference, MMM 2017. Presented at: MMM 2017; January 4-6, 2017; Reykjavik, Iceland. [ CrossRef ]
- Yang YC, Al-Garadi MA, Love JS, Perrone J, Sarker A. Automatic gender detection in Twitter profiles for health-related cohort studies. JAMIA Open. Jun 23, 2021;4(2):ooab042. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Yazdavar AH, Mahdavinejad MS, Bajaj G, Romine W, Sheth A, Monadjemi AH, et al. Multimodal mental health analysis in social media. PLoS One. Apr 10, 2020;15(4):e0226248. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Yildiz D, Munson J, Vitali A, Tinati R, Holland JA. Using Twitter data for demographic research. Demogr Res. Nov 22, 2017;37:1477-1514. [ CrossRef ]
- Zhang C, Xu S, Li Z, Hu S. Understanding concerns, sentiments, and disparities among population groups during the COVID-19 pandemic via Twitter data mining: large-scale cross-sectional study. J Med Internet Res. Mar 05, 2021;23(3):e26482. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Zhao Y, Zhang H, Huo J, Guo Y, Wu Y, Prosperi M, et al. Mining Twitter to assess the determinants of health behavior towards palliative care in the United States. AMIA Jt Summits Transl Sci Proc. 2020.:730-739. [ FREE Full text ] [ Medline ]
- Cesare N, Grant C, Hawkins JB, Brownstein JS, Nsoesie EO. Demographics in social media data for public health research: does it matter? arXiv. Preprint posted online October 30, 2017. 2023. [ FREE Full text ] [ CrossRef ]
- Rangel F, Rosso P, Koppel M, Stamatatos E, Inches G. Overview of the author profiling task at PAN 2013. In: Proceedings of the CLEF Conference on Multilingual and Multimodal Information Access Evaluation. Presented at: CLEF 2013; September 23-26, 2013; Valencia, Spain. URL: https://riunet.upv.es/handle/10251/46636
- Rangel F, Rosso P, Chugur I, Potthast M, Trenkmann M, Stein B, et al. Overview of the 2nd author profiling task at pan 2014. In: Proceedings of the 2014 Computer Science Workshops. Presented at: CEUR-WS '14; March 18, 2014; Sheffield, UK. URL: https://ceur-ws.org/Vol-1180/CLEF2014wn-Pan-RangelEt2014.pdf
- Rangel F, Celli F, Rosso P, Potthast M, Stein B, Daelemans W. Overview of the 3rd author profiling task at PAN 2015. In: Proceedings of the CLEF 2015 Conference and Labs of the Evaluation Forum. Presented at: CLEF 2015; September 8-11, 2015; Toulouse, France.
- Rangel F, Rosso P, Verhoeven B, Daelemans W, Potthast M, Stein B. Overview of the 4th author profiling task at PAN 2016: cross-genre evaluations. In: Proceedings of the Conference and Labs of the Evaluation Forum. Presented at: CLEF 2016; September 5-8, 2016; Evora, Portugal.
- Rangel F, Rosso P, Potthast M, Stein B. Overview of the 5th author profiling task at PAN 2017: gender and language variety identification in Twitter. In: Proceedings of the Conference and Labs of the Evaluation Forum. Presented at: CLEF 2017; September 11-14, 2017; Dublin, Ireland.
- Rangel F, Rosso P, Montes-y-Gómez M, Potthast M, Stein B. Overview of the 6th author profiling task at PAN 2018: multimodal gender identification in Twitter. In: Proceedings of the Conference and Labs of the Evaluation Forum. Presented at: CLEF 2018; September 10-14, 2018; Avignon, France.
- Rangel F, Rosso P. Overview of the 7th author profiling task at PAN 2019: bots and gender profiling in Twitter. In: Proceedings of the Conference and Labs of the Evaluation Forum. Presented at: CLEF 2019; September 9-12, 2019; Lugano, Switzerland.
- Burger JD, Henderson J, Kim G, Zarrella G. Discriminating gender on Twitter. In: Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. Presented at: EMNLP 2011; July 27-31, 2011; Edinburgh, UK. URL: https://aclanthology.org/D11-1120/
- Volkova S, Yarowsky D. Improving gender prediction of social media users via weighted annotator rationales. Johns Hopkins University. URL: https://hltcoe.jhu.edu/wp-content/uploads/2016/11/17310_slides.pdf [accessed 2023-03-30]
- Volkova S, Wilson T, Yarowsky D. Exploring demographic language variations to improve multilingual sentiment analysis in social media. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Presented at: EMNLP 2013; October 18-21, 2013; Seattle, WA.
- Liu W, Ruths D. What’s in a name? Using first names as features for gender inference in Twitter. In: Proceedings of the AAAI 2013 Spring Symposium Series. Presented at: AAAI 2013 Spring Symposium Series; March 25-27, 2013; Palo Alto, CA. URL: https://aaai.org/papers/05744-whats-in-a-name-using-first-names-as-features-for-gender-inference-in-twitter/
- Plank B, Hovy D. Personality traits on Twitter—or—how to get 1,500 personality tests in a week. In: Proceedings of the 6th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. Presented at: WASSA 2015; September 17, 2015; Lisboa, Portugal. [ CrossRef ]
- Verhoeven B, Daelemans W, Plank B. TwiSty: a multilingual twitter stylometry corpus for gender and personality profiling. In: Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16). Presented at: LREC'16; May 23-28, 2016; Portorož, Slovenia. URL: http://www.clips.uantwerpen.be/
- Chauhan A. Gender classification dataset. Kaggle. URL: https://www.kaggle.com/datasets/cashutosh/gender-classification-dataset [accessed 2022-10-17]
- Radford J. Piloting a theory-based approach to inferring gender in big data. In: Proceedings of the IEEE International Conference on Big Data (Big Data). Presented at: IEEE BigData 2017; December 11-14, 2017; Boston, MA. [ CrossRef ]
- Pizarro J. Using N-grams to detect Bots on Twitter Notebook for PAN at CLEF 2019. In: Proceedings of the Conference and Labs of the Evaluation Forum. Presented at: CLEF 2019; September 9-12, 2019; Lugano, Switzerland.
- Knowles R, Carroll J, Dredze M. Demographer: extremely simple name demographics. In: Proceedings of the First Workshop on NLP and Computational Social Science. Presented at: NLP+CSS 2016; November 5, 2016; Austin, Texas. [ CrossRef ]
- Volkova S, Coppersmith G, Van Durme B. Inferring user political preferences from streaming communications. In: Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Presented at: ACL 2014; June 22-27, 2014; Baltimore, MD. [ CrossRef ]
- Sap M, Park G, Eichstaedt JC, Kern ML, Stillwell D, Kosinski M, et al. Developing age and gender predictive lexica over social media. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Presented at: EMNLP 2014; October 25-29, 2014; Doha, Qatar. URL: https://aclanthology.org/D14-1121.pdf [ CrossRef ]
- Zhou E, Fan H, Cao Z, Jiang Y, Yin Q. Extensive facial landmark localization with coarse-to-fine convolutional network cascade. In: Proceedings of the IEEE International Conference on Computer Vision Workshops. Presented at: ICCV 2013; December 02-08, 2013; Sydney, Australia. URL: https://ieeexplore.ieee.org/document/6755923 [ CrossRef ]
- Wood-Doughty Z, Xu P, Liu X, Dredze M. Using noisy self-reports to predict Twitter user demographics. arXiv. Preprint posted online May 1, 2020. 2023. [ FREE Full text ] [ CrossRef ]
- Rothe R, Timofte R, Van Gool L. Deep expectation of real and apparent age from a single image without facial landmarks. Int J Comput Vis. Aug 10, 2016;126(2-4):144-157. [ CrossRef ]
- Wang R, Chaudhari P, Davatzikos C. Bias in machine learning models can be significantly mitigated by careful training: evidence from neuroimaging studies. Proc Natl Acad Sci U S A. Feb 07, 2023;120(6):e2211613120. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Geifman N, Cohen R, Rubin E. Redefining meaningful age groups in the context of disease. Age (Dordr). Dec 2013;35(6):2357-2366. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Sera LC, McPherson ML. Pharmacokinetics and pharmacodynamic changes associated with aging and implications for drug therapy. Clin Geriatr Med. May 2012;28(2):273-286. [ CrossRef ] [ Medline ]
- Gonzalez-Hernandez G, Weissenbacher D. Proceedings of the seventh workshop on social media mining for health applications, workshop and shared task. In: Proceedings of the Seventh Workshop on Social Media Mining for Health Applications, Workshop & Shared Task. Presented at: SMM4H '22; October 12-17, 2022; Gyeongju, Republic of Korea. URL: https://aclanthology.org/2022.smm4h-1.0/ [ CrossRef ]
- Distribution of Twitter users worldwide as of January, 2021, by gender. Statista. URL: https://www.statista.com/statistics/828092/distribution-of-users-on-twitter-worldwide-gender/
- Mauvais-Jarvis F, Bairey Merz N, Barnes PJ, Brinton RD, Carrero J, DeMeo DL, et al. Sex and gender: modifiers of health, disease, and medicine. Lancet. Aug 2020;396(10250):565-582. [ CrossRef ]
- Klein AZ, Magge A, Gonzalez-Hernandez G. ReportAGE: automatically extracting the exact age of Twitter users based on self-reports in tweets. PLoS One. 2022;17(1):e0262087. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Sloan L, Morgan J, Housley W, Williams M, Edwards A, Burnap P, et al. Knowing the tweeters: deriving sociologically relevant demographics from Twitter. Sociological Res Online. Aug 31, 2013;18(3):74-84. [ CrossRef ]
- Sloan L. Who tweets in the United Kingdom? Profiling the Twitter population using the British social attitudes survey 2015. Soc Media Soc. Mar 22, 2017;3(1):205630511769898. [ CrossRef ]
- Jung S, An J, Kwak H, Salminen J, Jansen B. Assessing the accuracy of four popular face recognition tools for inferring gender, age, and race. Proc Int AAAI Conf Web Soc Media. Jun 15, 2018;12(1). [ FREE Full text ] [ CrossRef ]
- Steyerberg EW, Harrell FE. Prediction models need appropriate internal, internal-external, and external validation. J Clin Epidemiol. Jan 2016;69:245-247. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Siontis GC, Ioannidis JP. Response to letter by Forike et al.: more rigorous, not less, external validation is needed. J Clin Epidemiol. Jan 2016;69:250-251. [ CrossRef ] [ Medline ]
- Borkotoky K, Unisa S. Indicators to examine quality of large scale survey data: an example through district level household and facility survey. PLoS One. 2014;9(3):e90113. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Basannar DR, Singh S, Yadav J, Yadav AK. Quantifying age heaping and age misreporting in a multicentric survey. Indian J Community Med. 2022;47(1):104-106. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Gupta S, Gupta A. Dealing with noise problem in machine learning data-sets: a systematic review. Procedia Comput Sci. 2019;161:466-474. [ CrossRef ]
- Karimi D, Dou H, Warfield SK, Gholipour A. Deep learning with noisy labels: exploring techniques and remedies in medical image analysis. Med Image Anal. Oct 2020;65:101759. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Golder S, Scantlebury A, Christmas H. Understanding public attitudes toward researchers using social media for detecting and monitoring adverse events data: multi methods study. J Med Internet Res. Aug 29, 2019;21(8):e7081. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Williams ML, Burnap P, Sloan L. Towards an ethical framework for publishing Twitter data in social research: taking into account users' views, online context and algorithmic estimation. Sociology. Dec 26, 2017;51(6):1149-1168. [ FREE Full text ] [ CrossRef ] [ Medline ]
- Singh L, Polyzou A, Wang Y, Farr J, Gresenz CR. Social media data - our ethical conundrum. Bulletin of the IEEE Computer Society Technical Committee on Data Engineerin. 2020. URL: http://sites.computer.org/debull/A20dec/p23.pdf [accessed 2023-03-30]
- Valdez R, Keim-Malpass J. Ethics in health research using social media. In: Bian J, Guo Y, He Z, Hu X, editors. Social Web and Health Research. Cham, Switzerland. Springer; 2019.
- Benton A, Coppersmith G, Dredze M. Ethical research protocols for social media health research. In: Proceedings of the First ACL Workshop on Ethics in Natural Language Processing. Presented at: EthNLP@EACL; April 4, 2017; Valencia, Spain. [ CrossRef ]
- McKee R. Ethical issues in using social media for health and health care research. Health Policy. May 2013;110(2-3):298-301. [ CrossRef ] [ Medline ]
Abbreviations
Edited by A Mavragani; submitted 05.04.23; peer-reviewed by B Ru, C Ni; comments to author 05.06.23; revised version received 28.07.23; accepted 01.08.23; published 15.03.24.
©Karen O'Connor, Su Golder, Davy Weissenbacher, Ari Z Klein, Arjun Magge, Graciela Gonzalez-Hernandez. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 15.03.2024.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in the Journal of Medical Internet Research, is properly cited. The complete bibliographic information, a link to the original publication on https://www.jmir.org/, as well as this copyright and license information must be included.
Profitability and working capital management: a meta-study in macroeconomic and institutional conditions
- Research Article
- Published: 14 March 2024
Cite this article
- Jacek Jaworski ORCID: orcid.org/0000-0002-6629-3497 1 &
- Leszek Czerwonka 2
3 Altmetric
Working capital management (WCM) concerns decisions on the levels and turnover of the inventories, receivables, cash and current liabilities of a company. Consequently, WCM affects the profitability of an enterprise. This paper aims to determine the relationship between profitability and WCM, characterised by components of the company’s operating cycle. The research is based on meta-analysis and meta-regression methods that allow for the combination and analysis of the outcomes of individual empirical studies using statistical methods. Our final research sample consists of 43 scientific papers from 2003 to 2018. These studies covered almost 62,000 enterprises in 35 countries from 1992 to 2017. Our results indicate that there is a common, negative relationship between profitability and the cash conversion cycle (CCC). This relationship is conspicuous in various countries and in different economic contexts. A negative, statistically significant relationship was also detected between profitability and average collection period (ACP), the accounts payable period (APP) and inventory turnover cycle (ITC) as well. We also identified moderators of the diagnosed dependencies on the grounds of macroeconomic and institutional factors. The richer the economy, the weaker a negative impact of CCC on profitability. The higher the protection of creditors and debtors, the weaker the negative relationship between profitability and ITC. The opposite is applicable to inflation and ACP and APP, unemployment and CCC, ACP and APP, the availability of credit and APP and the degree of capital market development and CCC and ACP. The aforementioned macroeconomic and institutional factors cause the negative relationship between particular components of the operating cycle and profitability to deepen even further. Our research contributes to the existing knowledge by confirming that the negative relationship between profitability and all components of the operating cycle is dominant in the global economy. It also indicates that there are macroeconomic and institutional moderators of the strength and direction of these relationships.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Source : Own elaboration based on (Brealey et al. 2016 )
Source : Own elaboration
Abuzayed B (2012) Working capital management and firms’ performance in emerging markets: the case of Jordan. Int J Manag Financ 8(2):155–179. https://doi.org/10.1108/17439131211216620
Article Google Scholar
Aggarwal A, Chaudhary R (2015) Effect of working capital management on the profitability of Indian firms. IOSR J Bus Manag 17(8):34–43
Google Scholar
Ahmed K, Courtis JK (1999) Associations between corporate characteristics and disclosure levels in annual reports: a meta-analysis. British Accounting Rev. https://doi.org/10.1006/bare.1998.0082
Alavinasab SM, Davoudi E (2013) Studying the relationship between working capital management and profitability of listed companies in Tehran stock exchange. Bus Manag Dynam 2(7):1–8. https://doi.org/10.1109/TLT.2009.30
Aloe A (2014) An empirical investigation of partial effect sizes in meta-analysis of correlational data. J Gen Psychol 141(1):47–64. https://doi.org/10.1080/00221309.2013.853021
Article PubMed Google Scholar
Alshammari T (2018) International journal of economics and financial issues performance effects of working capital in emerging markets. Int J Econ Financ Issues 8(5):80–87
Aregbeyen O (2013) The effects of working capital management on profitability of Nigerian manufacturing firms. J Bus Econ Manag 14(3):520–534. https://doi.org/10.3846/16111699.2011.651626
Baños-Caballero S, García-Teruel PJ, Martínez-Solano P (2012) How does working capital management affect the profitability of Spanish SMEs? Small Bus Econ 39(2):517–529. https://doi.org/10.1007/s11187-011-9317-8
Baños-Caballero S, García-Teruel PJ, Martínez-Solano P (2019) Net operating working capital and firm value: a cross-country analysis. BRQ Bus Res Quart, Press,. https://doi.org/10.1016/j.brq.2019.03.003
Bijmolt T, Pieters R (2001) Meta-analysis in marketing when studies contain multiple measurements. Mark Lett 12(2):157–169
Blinder AS, Maccini LJ (1991) The resurgence of inventory research: What have we learned? J Econ Surv 5:291–328
Brealey RA, Myers SC, Allen F (2016) Principles of corporate finance—principles of corporate finance (12th edition), 12th edn. McGraw-Hill Education, OH
Brown S, Homer P, Inman J (1998) A meta-analysis of relationships between ad-evoked feelings and advertising responses. J Mark Res 35:114–126
Chang CC (2018) Cash conversion cycle and corporate performance: Global evidence. Int Rev Econ Financ 56:568–581. https://doi.org/10.1016/j.iref.2017.12.014
Charitou M, Lois P, Santoso HB (2012) The relationship between working capital management and firm’s profitability: a empirical investigation for an emerging Asian country. Int Bus Econ Res J 11(8):839–849
Charitou MS, Elfani M, Lois P (2016) The effect of working capital management on firm’s profitability: empirical evidence from an emerging market. J Bus Econ Res 14(3):111–118
de Jong A, Kabir R, Nguyen TT (2008) Capital structure around the world: the roles of firm-and country-specific determinants. J Bank Financ 32:1954–1969. https://doi.org/10.1016/j.jbankfin.2007.12.034
Deloof M (2003) Does working capital management affect profitability of Belgian firms? J Bus Financ Acc. https://doi.org/10.1111/1468-5957.00008
Den M, Oruc E (2009) Relationship between efficiency level of working capital management and return on total assets in ISE (Istanbul Stock Exchange). Int J Bus Manag. https://doi.org/10.5539/ijbm.v4n10p109
Ding S, Guariglia A, Knight J (2013) Investment and financing constraints in China: does working capital management make a difference? J Bank Financ. https://doi.org/10.1016/j.jbankfin.2012.03.025
Duval SJ, Tweedie RL (2000) A nonparametric `trim and fill’ method of accounting for publication bias in meta-analysis. J Am Stat Assoc 95(449):89–98
MathSciNet Google Scholar
Eljelly AMA (2004) Liquidity—profitability tradeoff: an empirical investigation in an emerging market. Int J Commer Manag 14(2):48–61. https://doi.org/10.1108/10569210480000179
Erasmus PD (2010) Working capital management and profitability: the relationship between the net trade cycle and return on assets. Manag Dyn 19(1):2–10. https://doi.org/10.1016/j.tics.2008.07.006
García-Teruel PJ, Martínez-Solano P (2007) Effects of working capital management on SME profitability. Int J Manag Financ 3(2):164–177. https://doi.org/10.1108/17439130710738718
Geyer-Klingeberg J, Hang M, Rathgeber A (2020) Meta-analysis in finance research: opportunities, challenges, and contemporary applications. Int Rev Financ Anal. https://doi.org/10.1016/j.irfa.2020.101524
Gill A, Biger N, Mathur N (2010) The relationship between working capital management and profitability: evidence from the United States. Bus Econ J 10(1):1–9
Gitman LJ (1974) Estimating corporate liquidity requirements: a simplified approach. Financ Rev. https://doi.org/10.1111/j.1540-6288.1974.tb01453.x
Glass GV (1976) Primary, secondary, and meta-analysis of research. Educ Res. https://doi.org/10.1002/hlca.200390194
Hang M, Geyer-Klingeberg J, Rathgeber AW, Stöckl S (2018) Measurement matters—a meta-study of the determinants of corporate capital structure. Quart Rev Econ Financ 68:211–225. https://doi.org/10.1016/j.qref.2017.11.011
Hanji MB (2017) Meta-analysis in psychiatry research: fundamental and advanced methods. Apple Academic Press, Toronto; New Jersey
Book Google Scholar
Hoang TV (2015) Impact of capital management on firm profitability: the case of listed manufacturing firms on Ho chi minh stock exchange. Asian Econ Financ Rev 5(5):779–789. https://doi.org/10.18488/journal.aefr/2015.5.5/102.5.779.789
Hsieh C, Chen YW (2013) Working capital management and profitability of publicly traded Chinese companies. Asian Pacyfic J Econ Bus 17(1):1–11
Jaworski J, Czerwonka L (2018) Relationship between profitability and liquidity of enterprises listed on warsaw stock exchange. In: 35th International Scientific Conference on Economic and Social Development—Sustainability from an Economic and Social Perspective Book of Proceedings (pp 15–16). https://doi.org/10.2139/ssrn.2338107
Jaworski J, Czerwonka L (2019) Meta-study on relationship between macroeconomic and institutional environment and internal determinants of enterprises’ capital structure. Econ Res-Ekonomska Istrazivanja 32(1):2614–2637. https://doi.org/10.1080/1331677X.2019.1650653
Jose ML, Lancaster C, Stevens JL (1996) Corporate returns and cash conversion cycles. J Econ Financ 20(1):33–46. https://doi.org/10.1007/BF02920497
Karaduman HA, Akbas HE, Ozsozgun A, Durer S (2010) Effects of working capital management on profitability: the case for selected companies in the Istanbul stock exchange (2005–2008). Int J Econ Financ Stud 2(2):48–54
Keskin R, Gokalp F (2016) The effects of working capital management on firm’s profitability: panel data analysis. Doğuş Üniversitesi Dergisi 17(1):15–25
Kieschnick RL, Laplante M, Moussawi R (2011) Working capital management and shareholder wealth. Rev Financ 17(5):1827–1852.
Kroes JR, Manikas AS (2014) Cash flow management and manufacturing firm financial performance: a longitudinal perspective. Int J Prod Econ. https://doi.org/10.1016/j.ijpe.2013.11.008
Kusuma H, Dhiyaullatief Bachtiar A (2018) Working capital management and corporate performance: evidence from Indonesia. J Manag Bus Administ. Central Europe, 26(2): 76–88
Lazaridis I, Tryfonidis D (2006) Relationship between working capital management and profitability of listed companies in the athens stock exchange. J Financ Manag Anal 19(l): 26–35
Li CG, Dong HM, Chen S, Yang Y (2014) Working capital management, corporate performance, and strategic choices of the wholesale and retail industry in China. Scientific World J. https://doi.org/10.1155/2014/953945
Lin TT (2015) Working capital requirement and the unemployment volatility puzzle. J Macroecon 46:201–217. https://doi.org/10.1016/j.jmacro.2015.05.006
Article CAS Google Scholar
Littell JH, Corcoran J, Pillai V (2008) Systematic reviews and meta analysis. Oxford Univ Press. https://doi.org/10.1093/acprof
Lyngstadaas H, Berg T (2016) Working capital management: evidence from Norway. Int J Manag Financ 12(3):295–313. https://doi.org/10.1108/IJMF-01-2016-0012
Mansoori E, Muhammad J (2012) The effect of working capital management on firm’s Profitability. Interdiscip J Contemporary Res Bus, pp 472–486
Mathuva DM (2010) The influence of working capital management components on corporate profitability: a survey on Kenyan listed firms. Res J Bus Manag 4(1):1–11. https://doi.org/10.3923/rjbm.2010.1.11
Michaelas N, Chittenden F, Poutziouris P (1999) Financial policy and capital structure choice in UK SMEs: evidence from company panel data. Small Bus Econ 12:113–130
Mokhova N, Zinecker M (2014) Macroeconomic factors and corporate capital structure. Procedia Soc Behav Sci 110:530–540. https://doi.org/10.1016/j.sbspro.2013.12.897
Napompech K (2012) Effect of Wcm on the profitability of thai firm. Int J Trade, Ecnomics Financ 3(3):227–232
Ng SH, Ye C, Ong TS, Teh BH (2017) The impact of working capital management on firm’s profitability: evidence from Malaysian listed manufacturing firms. Int J Econ Financ Issues 7(3):662–670. https://doi.org/10.11114/afa.v4i1.2949
Nobanee H, Abdullatif M, Alhajjar M (2011) Cash conversion cycle and firm’s performance of Japanese firms. Asian Rev Account 19(2):147–156. https://doi.org/10.1108/13217341111181078
North D (1990) Institutions, institutional change and economic performance. Harvard University Press, Cambridge
Nyamweno CN, Olweny T (2014) Effect of working capital management on performance of firms listed at the Nairobi securities exchange. Econ Financ Rev 3(11):1–14
Padachi K (2006) Trends in working capital management and its impact on firms’ performance: an analysis of Mauritian small manufacturing firms. Int Rev Bus Res Papers 2(2):45–58
Pais MA, Gama PM (2015) Working capital management and SMEs profitability: Portuguese evidence. Int J Manag Financ 11(3):341–358. https://doi.org/10.1108/IJMF-11-2014-0170
Peterson R (1994) A meta-analysis of Cronbach’s coefficient alpha. J Consumer Res 21:381–391
R Core Team (2019) R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/
Raheman A, Afza T, Qayyum A, Bodla M (2010) Working capital management and corporate performance of manufacturing sector in Pakistan. Int Res J Financ Econ 47(1):156–169
Rosenthal R (1991) Meta-analytic procedures for social research. Sage, Newbury Park
Ross S, Westerfield RW, Jordan BD (2013) Fundementals of corporate finance 10e. In McGraw-Hill Irwin, New York
Saldanli A (2012) The relationship between liquidity and profitability—an empirical study on the ISE-100 manufacturing sector. J Suleyman Demirel Univ Inst Soc Sci 16:167–176
Şamiloğlu F, Akgün Aİ (2016) The relationship between working capital management and profitability: evidence. Bus Econ Res J 7(2):1–14
Schmidt FL, Hunter JE (2004) Methods of meta-analysis: correcting error and bias in research findings. In: Methods of Meta-Analysis: Correcting Error and Bias in Research Findings (2nd edition). Thousand Oaks. https://doi.org/10.4135/9781483398105
Sethuraman R (1995) A meta-analysis of national brand and store brand cross-promotional price elasticities. Mark Lett 6(4):275–286
Shelby LB, Vaske J (2008) Understanding meta-analysis: a review of the methodological literature. Leis Sci. https://doi.org/10.1080/01490400701881366
Shin H-H, Soenen L (1998) Efficiency of working capital management and corporate profitability. Financ Pract Educ 8(2):37–45. https://doi.org/10.1002/(SICI)1099-0518(20000515)38:10%3c1753::AID-POLA600%3e3.0.CO;2-O
Shrivastava A, Kumar N, Kumar P (2017) Bayesian analysis of working capital management on corporate profitability: evidence from India. J Econ Stud 44(4):568–584. https://doi.org/10.1108/JES-11-2015-0207
Singh HP, Kumar S, Colombage S (2017) Working capital management and firm profitability: a meta-analysis. Qualitat Res Financ Mark 9(1):34–47. https://doi.org/10.1108/QRFM-06-2016-0018
Smith K (1980) Profitability versus liquidity tradeoffs in working capital management. In: Smith K (ed) Readings on the management of working capital. West Publishing Company, St. Paul, pp 549–562
Smith JK (1987) Trade credit and informational asymmetry. J Financ 42:863–872
Suurmond R, van Rhee H, Hak T (2017) Introduction, comparison, and validation of meta-essentials: a free and simple tool for meta-analysis. Res Synthesis Methods. https://doi.org/10.1002/jrsm.1260
Tauringana V, Adjapong Afrifa G (2013) The relative importance of working capital management and its components to SMEs’ profitability. J Small Bus Enterp Dev 20(3):453–469. https://doi.org/10.1108/JSBED-12-2011-0029
Tran H, Abbott M, Jin Yap C (2017) How does working capital management affect the profitability of Vietnamese small-and medium-sized enterprises? J Small Bus Enterp Dev 24(1):2–11. https://doi.org/10.1108/JSBED-05-2016-0070
Troilo M, Walkup BR, Abe M, Lee S (2019) Legal systems and the financing of working capital. Int Rev Econ Financ 64:641–656. https://doi.org/10.1016/j.iref.2018.01.010
Ugurlu E, Jindrichovska I, Kubickova D (2014) Working capital management in Czech SMEs : an econometric approach. Procedia Econ Business Administrat, pp 311–317
Ukaegbu B (2014) The significance of working capital management in determining firm profitability: evidence from developing economies in Africa. Res Int Bus Financ 31:1–16. https://doi.org/10.1016/j.ribaf.2013.11.005
Vahid TK, Elham G, Mohsen A, khosroshahi, Mohammadreza, E (2012) Working capital management and corporate performance: evidence from Iranian companies. Procedia Soc Behav Sci 62:1313–1318. https://doi.org/10.1016/j.sbspro.2012.09.225
Valipour H, Jamshidi A (2012) Determining the optimal efficiency index of working capital management and its relationship with efficiency of assets in categorized industries: evidence from Tehran stock exchange ( TSE ). Adv Manag Appl Econ 2(2):191–209
Viechtbauer W (2010) Conducting meta-analyses in R with the metafor package. J Statist Softw 36(3):1–48
Vural G, Sokmen AG, Cetenak E (2012) Affects of working capital management on firm’s performance: evidence from Turkey. Int J Econ Financ Issues 2(4):488–495
Wöhrmann A, Knauer T, Gefken J (2012) Kostenmanagement in Krisenzeiten: rentabilitätssteigerung durch working capital management? Zeitschrift Für Controll Manag 56:83–88. https://doi.org/10.1365/s12176-012-0649-2
Yazdanfar D, Öhman P (2014) The impact of cash conversion cycle on firm profitability: an empirical study based on Swedish data. Int J Manag Financ 10(4):442–452. https://doi.org/10.1108/IJMF-12-2013-0137
Yunos RM, Nazaruddin N, Ghapar FA, Ahmad SA, Zakaria NB (2015) Working capital management in Malaysian government-linked companies. Procedia Econ Financ 31(15):573–580. https://doi.org/10.1016/S2212-5671(15)01203-4
Download references
There are no special grants and institutions supporting submitted study.
Author information
Authors and affiliations.
Faculty of Business, WSB Merito University in Gdańsk, Al. Grunwaldzka 238A, 80-266, Gdańsk, Poland
Jacek Jaworski
Faculty of Economics, University of Gdańsk, ul. Armii Krajowej 119, 81-824, Sopot, Poland
Leszek Czerwonka
You can also search for this author in PubMed Google Scholar
Contributions
Both authors contributed to the study conception and design. JJ is especially responsible for literature review and research question and hypotheses formulation, whereas LC for empirical study elaboration. Discussion and conclusions are the results of common work.
Corresponding authors
Correspondence to Jacek Jaworski or Leszek Czerwonka .
Ethics declarations
Conflict of interest.
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.

Source : Own elaboration (in metafor R package)
Funnel plots of standard error by partial correlation coefficient (Fisher’s z transformed) ratio for studies included in meta-analysis (after trimming and filling).
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Jaworski, J., Czerwonka, L. Profitability and working capital management: a meta-study in macroeconomic and institutional conditions. Decision (2024). https://doi.org/10.1007/s40622-023-00372-x
Download citation
Accepted : 08 December 2023
Published : 14 March 2024
DOI : https://doi.org/10.1007/s40622-023-00372-x
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Meta-analysis
- Profitability
- Working capital management
- Cash conversion cycle
- Meta-regression
- Macroeconomic and institutional factors
- Find a journal
- Publish with us
- Track your research
IMAGES
VIDEO
COMMENTS
The discussion section is where you delve into the meaning, importance, and relevance of your results.. It should focus on explaining and evaluating what you found, showing how it relates to your literature review and paper or dissertation topic, and making an argument in support of your overall conclusion.It should not be a second results section.. There are different ways to write this ...
Tips to Write the Results Section. Direct the reader to the research data and explain the meaning of the data. Avoid using a repetitive sentence structure to explain a new set of data. Write and highlight important findings in your results. Use the same order as the subheadings of the methods section.
Begin with a clear statement of the principal findings. This will reinforce the main take-away for the reader and set up the rest of the discussion. Explain why the outcomes of your study are important to the reader. Discuss the implications of your findings realistically based on previous literature, highlighting both the strengths and ...
Discussion Phrases Guide. Papers usually end with a concluding section, often called the "Discussion.". The Discussion is your opportunity to evaluate and interpret the results of your study or paper, draw inferences and conclusions from it, and communicate its contributions to science and/or society. Use the present tense when writing the ...
The results section of a research paper tells the reader what you found, while the discussion section tells the reader what your findings mean. The results section should present the facts in an academic and unbiased manner, avoiding any attempt at analyzing or interpreting the data. Think of the results section as setting the stage for the ...
The discussion section is one of the final parts of a research paper, in which an author describes, analyzes, and interprets their findings. They explain the significance of those results and tie everything back to the research question(s). In this handout, you will find a description of what a discussion section does, explanations of how to ...
The discussion section provides an analysis and interpretation of the findings, compares them with previous studies, identifies limitations, and suggests future directions for research. This section combines information from the preceding parts of your paper into a coherent story. By this point, the reader already knows why you did your study ...
Making scientific research available to others is a key part of academic integrity and open science. Interpretation or discussion of results; This belongs in your discussion section. Your results section is where you objectively report all relevant findings and leave them open for interpretation by readers.
After a research article has presented the substantive background, the methods and the results, the discussion section assesses the validity of results and draws conclusions by interpreting them. The discussion puts the results into a broader context and reflects their implications for theoretical (e.g. etiological) and practical (e.g ...
Tips for Writing the Discussion Section. Start with the big picture - WHY is your study important? o Think of yourself as telling the story of how your findings answer the question you posed and why your findings matter, how your field's status quo or understanding is changed by your results. o Clearly signal that you are answering the ...
Results and Discussion Sections in Scientific Research Reports (IMRaD) After introducing the study and describing its methodology, an IMRaD* report presents and discusses the main findings of the study. In the results section, writers systematically report their findings, and in discussion, they interpret these findings.
The discussion should also address the study's research questions and explain how the results contribute to the field of study. Limitations: This section should acknowledge any limitations of the study, such as sample size, data collection methods, or other factors that may have influenced the results.
This handout was created to accompany the Writing in the Sciences video series. The purpose of the Results is to prepare readers for the discussion section by presenting the data in manageable chunks, in an order that corresponds with the research questions or objectives. The purpose of the Discussion section is used to contain analysis and ...
Begin the Discussion section by restating your statement of the problem and briefly summarizing the major results. Do not simply repeat your findings. Rather, try to create a concise statement of the main results that directly answer the central research question that you stated in the Introduction section.
Don't repeat results. Order simple to complex (building to conclusion); or may state conclusion first. Conclusion should be consistent with study objectives/research question. Explain how the results answer the question under study. Emphasize what is new, different, or important about your results.
The Discussion section is an important part of the research manuscript that allows the authors to showcase the study. It is used to interpret the results for readers, describe the virtues and ...
Background: The scientific article in the health sciences evolved from the letter form and purely descriptive style in the seventeenth century to a very standardized structure in the twentieth century known as introduction, methods, results, and discussion (IMRAD). The pace in which this structure began to be used and when it became the most used standard of today's scientific discourse in the ...
The discussion section is where you delve into the meaning, importance, and relevance of your results.. It should focus on explaining and evaluating what you found, showing how it relates to your literature review, and making an argument in support of your overall conclusion.It should not be a second results section.. There are different ways to write this section, but you can focus your ...
This article speaks about the best ways in writing results and discussion section during your research work. Charlesworth Author Services, a trusted brand supporting the world's leading academic publishers, institutions and authors since 1928. We only work with native English-speaking editors with advanced or postdoctoral degrees in their disciplines.
Discussion. The Discussion section explains why the results described in the previous section are meaningful in relation to previous scholarly work and the specific research question your paper explores. This section usually includes: Engagement with sources that are relevant to your work (you should compare and contrast your results to those of similar researchers)
The Results and Discussion sections can be written as separate sections (as shown in Fig. 2), but are often combined in a poster into one section called Results and Discussion. This is done in order to (1) save precious space on a poster for the many pieces of information that a scientist would like to tell their audience and (2) by combining the two sections, it becomes easier for the ...
This chapter 5 presents the results of the study. First, an outline of the informants included in the study and an overview of the statistical techniques employed in the data analyses are given ...
This section describes the research design, sources of data, sampling procedure, sample size, as well as the methods of data analysis used in this study. A representative sample of economics students enrolled in a 3-year undergraduate programme at the University of Rwanda. The target population consisted of all 311 enrolled students.
The use of corticosteroids for esophageal strictures remains inconclusive, demanding further robust research. The research addressed a critical gap in the existing literature by specifically examining the outcomes of caustic ingestion in the context of an 11-year-long conflict in Syria, underscoring the importance of effective treatment strategies.
Participant characteristics. A total of 84 participants consented to participate in the study. Most participants were female [86%], and their mean age was 39.7 [SD = 9.2; range: 22-60; missing n = 3].Participants' years of experience as registered nurses ranged from 0 [i.e., less than 1 year's experience] to 39, with a mean of 13.9 [SD = 9.0, missing n = 3]; while their years of experience ...
Background: Patient health data collected from a variety of nontraditional resources, commonly referred to as real-world data, can be a key information source for health and social science research. Social media platforms, such as Twitter (Twitter, Inc), offer vast amounts of real-world data. An important aspect of incorporating social media data in scientific research is identifying the ...
The research is based on meta-analysis and meta-regression methods that allow for the combination and analysis of the outcomes of individual empirical studies using statistical methods. Our final research sample consists of 43 scientific papers from 2003 to 2018. These studies covered almost 62,000 enterprises in 35 countries from 1992 to 2017.